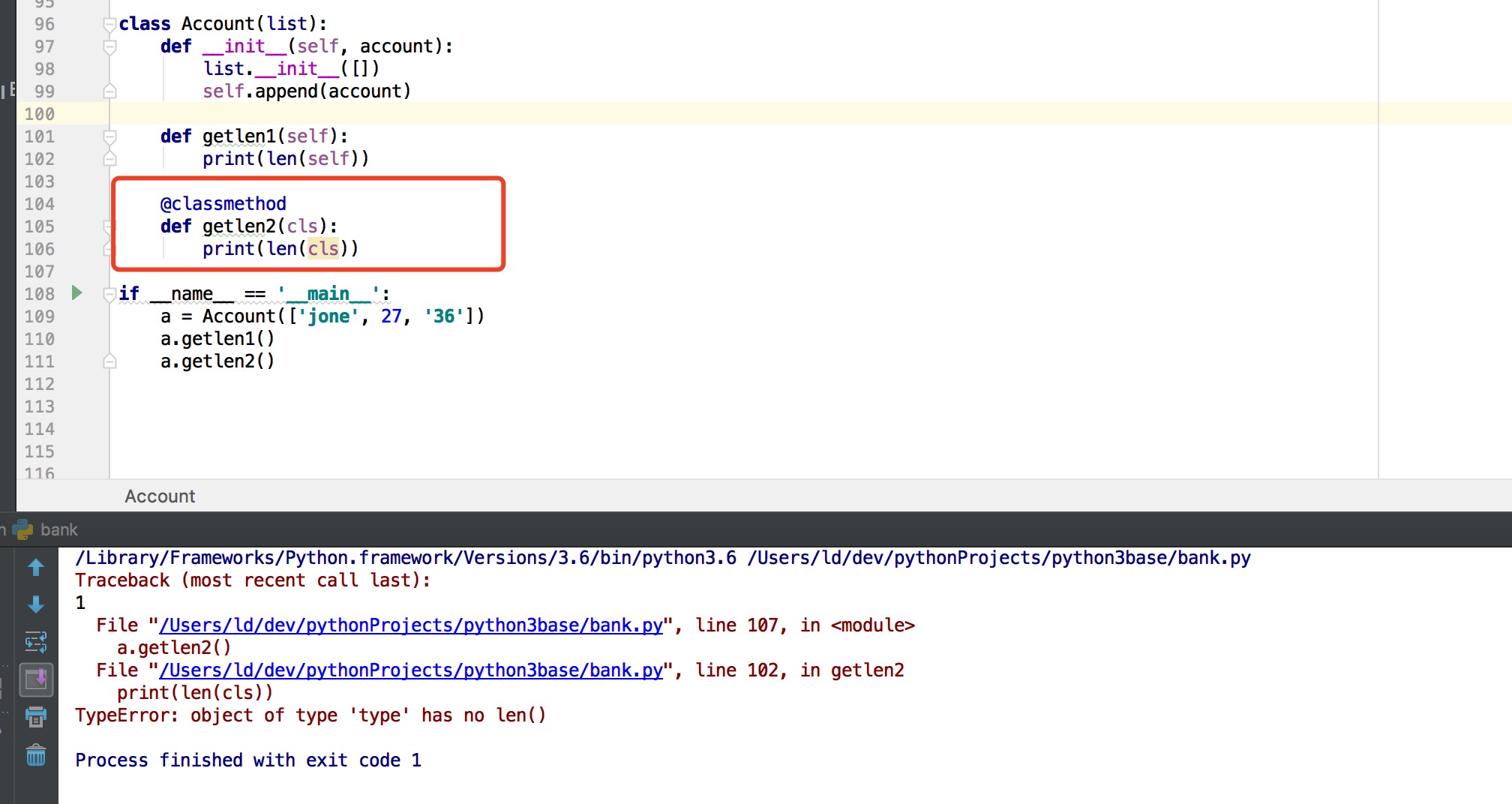
Python的类继承dict、list、set之后,该类的类方法怎么获取它的长度?
class Account(list):
def __init__(self, account):
list.__init__([])
self.append(account)
def getlen1(self):
print(len(self))
@classmethod
def getlen2(cls):
print(len(cls))
if __name__ == '__main__':
a = Account(['jone', 27, '36'])
a.getlen1()
a.getlen2()
执行方法2会报错: