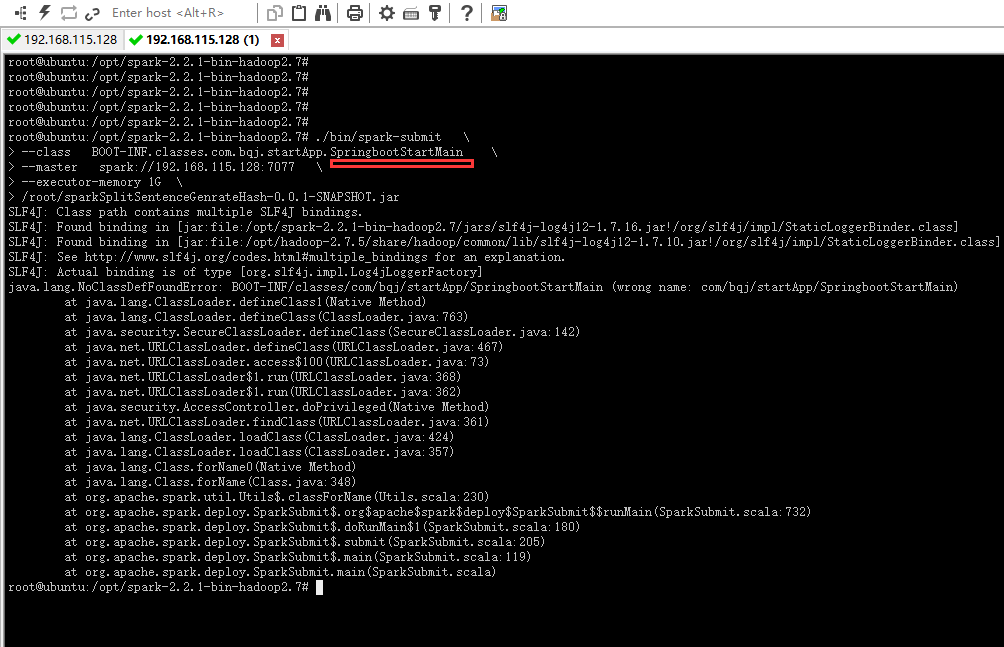

我想用spark-submit提交个springboot的jar包,指定运行main函数是遇到了问题

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
 hongyaodi5175 2018-01-05 02:32关注
hongyaodi5175 2018-01-05 02:32关注1、临时解决方法:将spark/work目录下的文件手动删除,之后重新提交application就可以了。
2、修改spark配置文件:在spark-env.sh中加入如下内容
SPARK_WORKER_OPTS=”-Dspark.worker.cleanup.enabled=true”
这样,spark会自动清除已经停止运行的application的文件夹。如果是application一直在运行的话,就会持续向work目录写数据,这样work目录下的文件还是会越来越大
并最终无法写入。因此最好是以上两个方法同时使用,定期手工清理work目录下的文件。本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2021-02-24 05:34weixin_39716800的博客 I know this is a trivial question, but I could not find the answer on the internet.I am trying to run a Java class with the main function with program arguments (String[] args).However, when I submit ...
- 2017-08-14 15:12叶不二的博客 找到spark-submit文件的目录 目录/spark-submit --master spark://192.168.172.10:7077 --executor-memory 2g --total-executor-cores 10 --driver-memory 4G --class com.test.main.test test.jar参数: --...
- 2020-12-09 13:04weixin_39982269的博客 最近刚学习spark,用spark-submit命令提交一个python脚本,一开始老报错,所以打算好好整理一下用spark-submit命令提交python脚本的过程。先看一下spark-submit的可选参数1.spark-submit参数--masterMASTER_URL:设置...
- 2021-02-11 10:08Blinkfire的博客 最近刚学习spark,用spark-submit命令提交一个python脚本,一开始老报错,所以打算好好整理一下用spark-submit命令提交python脚本的过程。先看一下spark-submit的可选参数1.spark-submit参数--masterMASTER_URL:设置...
- 2024-06-19 00:17gaohongfeng1的博客 这个命令会自动处理依赖树。当然,你也可以从距离工作节点很...这意味着,不会占用网络IO,特别是对一些大文件或jar包,最好使用这种方式,当然,你需要把文件推送到每个工作节点上,或者通过NFS和GlusterFS共享文件。
- 2024-11-22 20:25Vez'nan的幸福生活的博客 3)启动的Executor 进程 会主动与 Driver端通信,Driver 端根据代码的执行情况,产生多个task,发送给Executor;...运行 Application 的 main() 函数的节点,提交任务,并下发计算任务;spark的集群运行结构。
- 2021-03-08 18:10Microsoft资讯的博客 我知道这是一个微不足道的...但是,当我使用spark submit提交并传递程序参数提交作业时java -cp .jar 它不读取参数。我尝试运行的命令是bin/spark-submit analytics-package.jar --class full.package.name.Class...
- 2020-05-26 15:44MieuxLi的博客 1、提交python文件,遇到的难点是python文件缺乏运行所需要的依赖模块。 python3-mpipinstallxx 我使用的是将anaconda打包放在HDFS上。 基础是已经有同事在linux服务器上安装好了anaconda2,很方便。 首先是将...
- 2020-12-10 13:48weixin_39917811的博客 最近刚学习spark,用spark-submit命令提交一个python脚本,一开始老报错,所以打算好好整理一下用spark-submit命令提交python脚本的过程。先看一下spark-submit的可选参数1.spark-submit参数--masterMASTER_URL:设置...
- 2019-08-27 21:50丧心病狂の程序员的博客 本文介绍了使用java开发spark sql应用程序提交到yarn上运行的全过程,并介绍解决了一些开发和提交中常见的问题。 准备 首先我们要搭建好spark on yarn的集群环境,我是用cdh安装和cloudera manager进行维护的。 ...
- 没有解决我的问题, 去提问

问题事件
 已采纳回答
1月12日
已采纳回答
1月12日