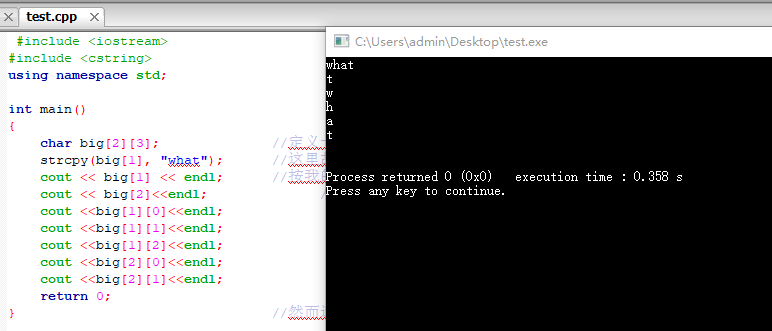
不明白运行的结果是怎么来的。二维数组的具体存储方式是怎样的啊
小白真心求助,提前谢过
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char big[2][3]; //定义一个2行3列的数组,应该对吧。。
strcpy(big[1], "what"); //这里故意来个了4个字节的,超出一个。
cout << big[1] << endl; //按我的理解,这里应该输出 wha (因为只能称下3个嘛)
cout << big[2]; //然后这里输出 t
return 0;
} //然而运行的结果并不是我想象的那样!!
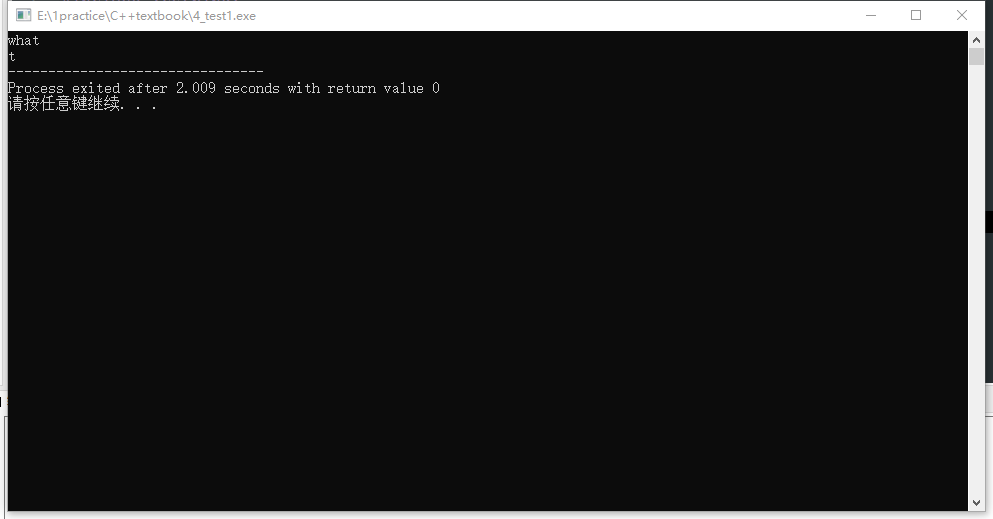
为什么第一行多了一个 t 啊.. 而且这里输出也就算了,然而第二行又输出一个 t 这不就重复了么..