
我用的是visual studio2017,自带安装的Anaconda2,pip安装的opencv-python,在我调用imshow函数的时候总是报错
cv2.error
Message=C:\projects\opencv-python\opencv\modules\highgui\src\window.cpp:331: error: (-215) size.width>0 && size.height>0 in function cv::imshow
StackTrace:
中的 C:\Users\Administrator\source\repos\PythonApplication1\PythonApplication1\PythonApplication1.py:4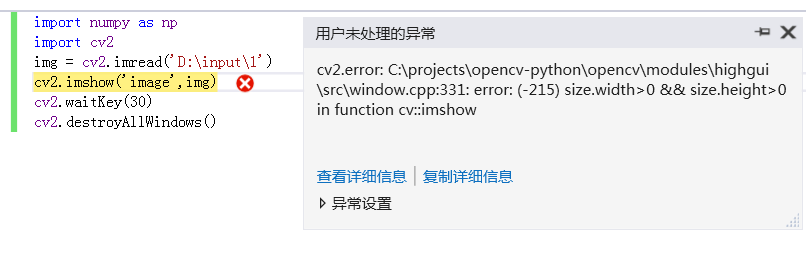

求大佬帮忙解答下





