第一天学习爬虫就遇到了这个问题,在网上找了很多解决办法都解决不了,希望有人能帮忙解决一下,感谢!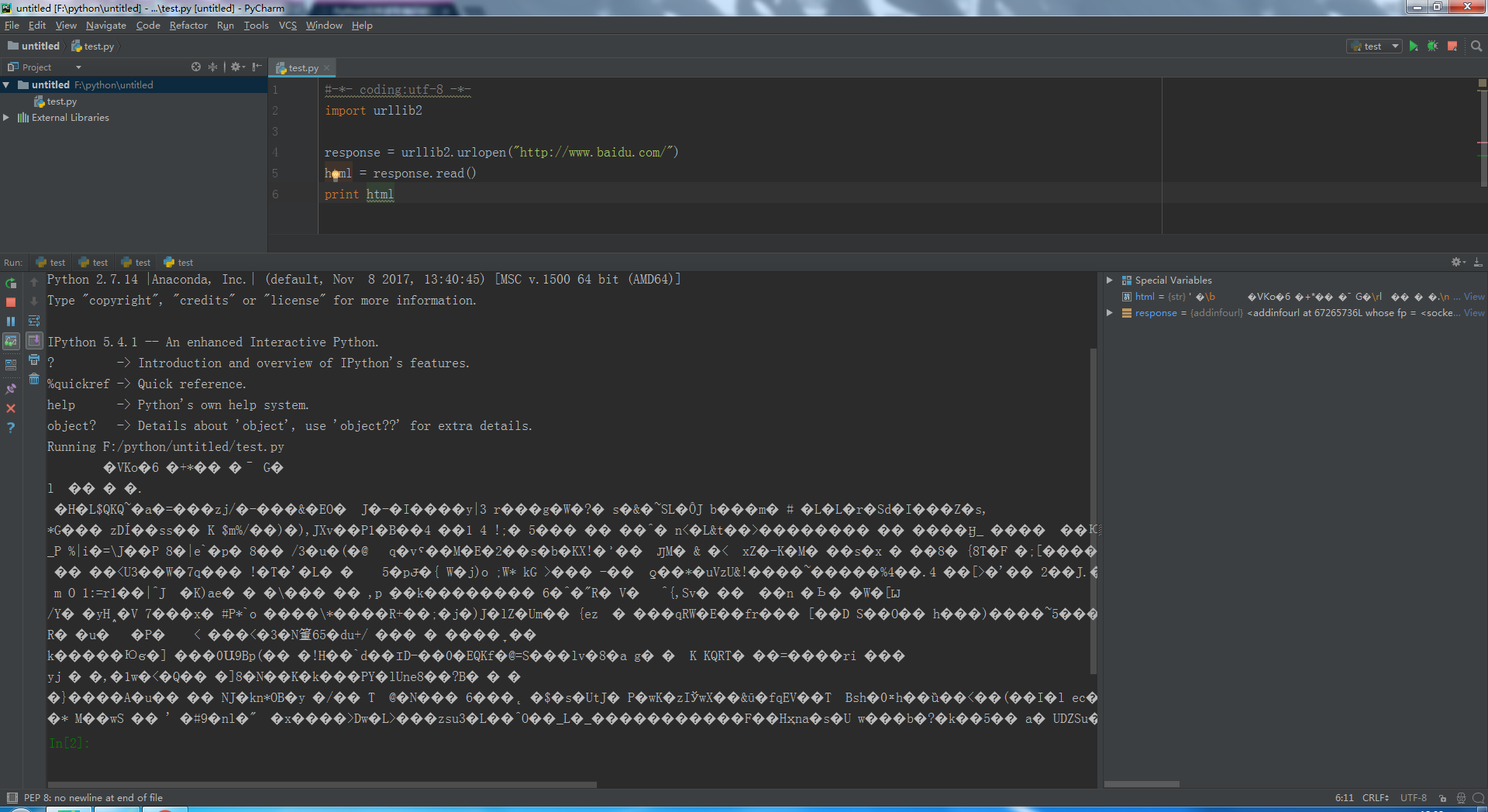

python爬虫编码问题 怎么都改不好

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


6条回答 默认 最新

- 2022-04-20 16:13回答 2 已采纳 with open ("mybaidu.html", mode = "w", encoding = "utf-8")这里面填一个encoding就好了
- 2022-04-29 11:12回答 1 已采纳 我给你改了一下,你对比看看吧: from bs4 import BeautifulSoup import pandas as pd import requests def crawer_travel
- 2022-08-15 09:11回答 1 已采纳 应该是css选择器里面的规则不够明确,可改成href = selectors.css('div.container div div div ul li a::attr(href)').getall()
- 2021-10-17 13:35五包辣条!的博客 上次整理的爬虫教程反响不错,但是还是有小伙伴表示不够细致,今天带了升级版,全文很长,建议先收藏下来。 一、爬虫基础 爬虫概述 知识点: 了解 爬虫的概念 了解 爬虫的作用 了解 爬虫的分类 ...
- 2023-03-08 13:31回答 2 已采纳 该回答引用GPTᴼᴾᴱᴺᴬᴵ如果您想要提取 div class="detail-context"标签下所有的 tr 标签,并进一步提取每个 tr 中的 td 标签内的内容,可以使用以下代码: impo
- 2023-04-13 13:18回答 1 已采纳 爬虫严格来讲并不算一个大方向,更偏向于js逆向,python的话推荐走后端方向至于系统学习的话,推荐去blibili找一些路线,然后根据路线去找bilibili上播放量比较高的视频进行系统学习
- 2022-03-18 12:30回答 2 已采纳 driver.swith_to.window(driver.window_handles[1]),函数名写错了,不是swith是switch,少写了个c,改成:driver.switch_to.win
- 2022-01-18 10:17Begin to change的博客 最近在学习爬虫,但是关于解码和编码的问题上出现了一些问题,百度了一下,终于找到了问题的解决办法 爬取网页时,自己用的明明是utf-8的编码(第一行的注释为utf-8,编码中的编码格式也是utf-8),但是还是报gbk的...
- 2022-07-22 11:10回答 2 已采纳 控制台 pip install requests
- 2022-10-09 11:41回答 2 已采纳
- 2022-08-17 17:07回答 3 已采纳 因为元素里的你要的内容是通过 ajax 请求动态加载的,可以浏览器抓包去看下,你想要的这条数据到底是哪个请求返回的,找到真正的请求,然后模拟发送就行了
- 2022-06-24 19:43回答 1 已采纳 其实有的,但是这个网站应该是为了懒加载把url用base64密了一下,然后再动态加载, 其实我下面发的这个就是url 是base64后的url 解码后就是https://s1.aigei.com/
- 2022-09-18 19:16AudiA6LV6的博客 0x04 动态页面的反爬虫 上述的几种情况大多都是出现在静态页面,还有一部分网站,我们需要爬取的数据是通过ajax请求得到,或者通过JavaScript生成的。首先用Firebug或者HttpFox对网络请求进行分析。如果能够找到...
- 2022-07-18 12:25提莫种西瓜的博客 需要的Python模块:requests(爬虫主体)、re(正则获取)、json(字符串转json)。 首先要通过浏览器或者抓包工具获取到该网站返回的数据集: 然后要把这只爬虫包装地更拟人化,即加上一些用户消息头(User-Agent...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 多电路系统共用电源的串扰问题
- ¥15 shape_predictor_68_face_landmarks.dat
- ¥15 slam rangenet++配置
- ¥15 有没有研究水声通信方面的帮我改俩matlab代码
- ¥15 对于相关问题的求解与代码
- ¥15 ubuntu子系统密码忘记
- ¥15 信号傅里叶变换在matlab上遇到的小问题请求帮助
- ¥15 保护模式-系统加载-段寄存器
- ¥15 电脑桌面设定一个区域禁止鼠标操作
- ¥15 求NPF226060磁芯的详细资料