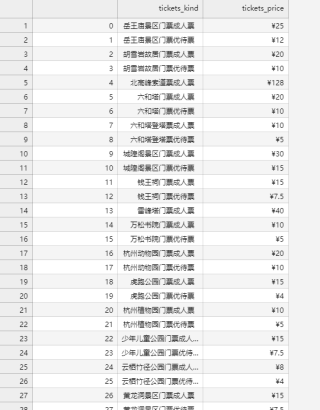
我想爬取西湖的门票种类和价格,但是爬取的内容为空,不知道哪方面出了问题,求解
代码如下:
from bs4 import BeautifulSoup
import pandas as pd
import requests
def crawer_travel_introduction(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req = requests.get(url, headers=headers)
content = req.text
bsObj = BeautifulSoup(content, 'lxml')
return bsObj
def get_jd_introduction(url):
cat_tickets_kind = []
cat_tickets_price= []
bsobj = crawer_travel_introduction(url)
bs = bsobj.find_all('dl', {'class': 'clrfix '})
for j in range(0, len(bs)):
# try:
name = bs[j].find('dt')
cat_tickets_kind.append(name.text)
price = bs[j].find('dd',{'class': 'e_old_price'}).find('del')
cat_tickets_price.append(price.text)
# except:
# print('wrong')
return cat_tickets_kind, cat_tickets_price
url = 'http://travel.qunar.com/p-oi708952-xihu'
cat_tickets_kind, cat_tickets_price = get_jd_introduction(url)
city = pd.DataFrame({'tickets_kind': cat_tickets_kind, 'tickets_price': cat_tickets_price})
city.to_csv('travel_introduction.csv', encoding='utf-8')