
我以一个类似的情况来提问,也是论坛中有个网友1年前提出的问题,但是他没有写出后续....
网页地址:http://www.lzggzyjy.cn/InfoPage/InfoList.aspx?SiteItem=8
需求:python post请求获取该页面(感觉很简单)
分析页面: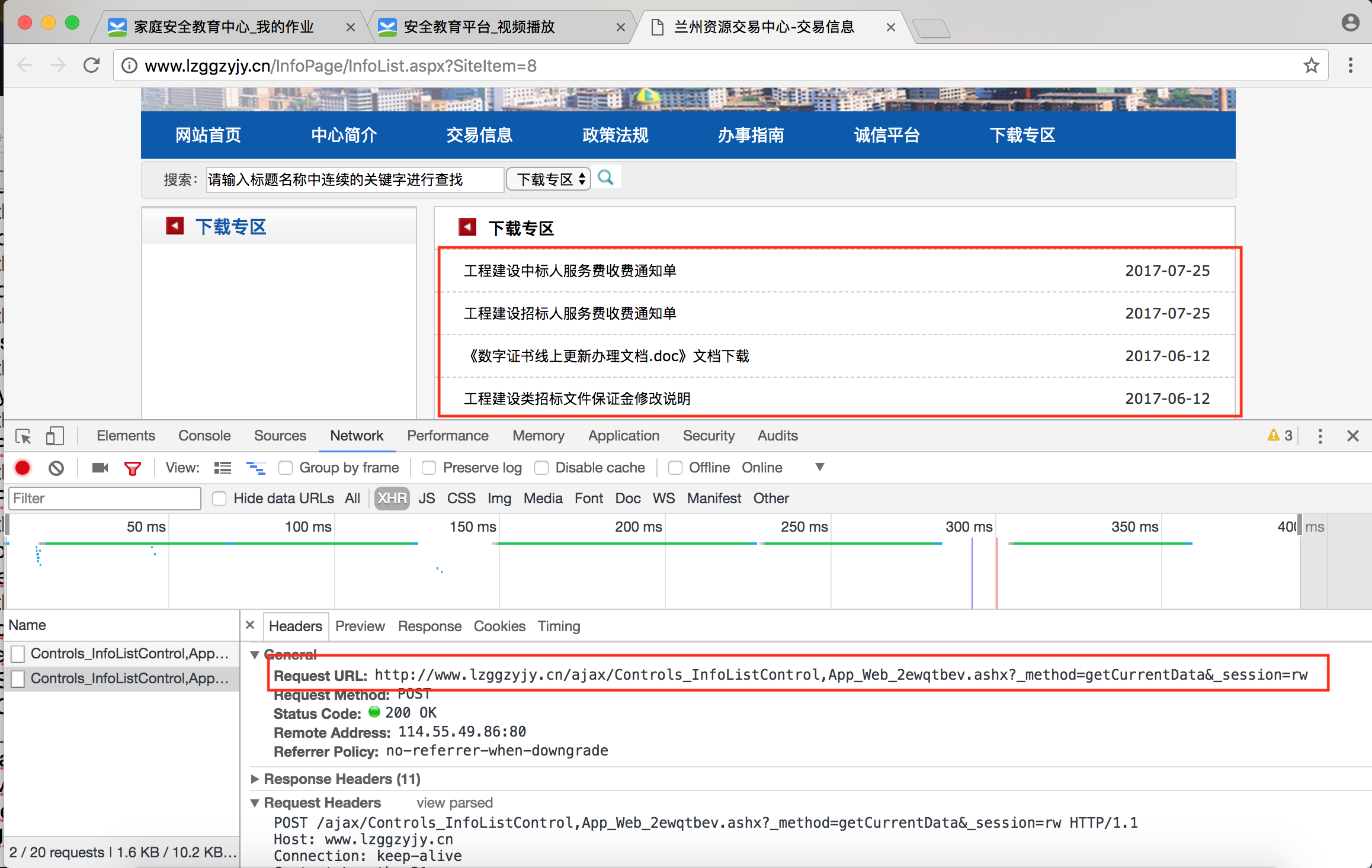
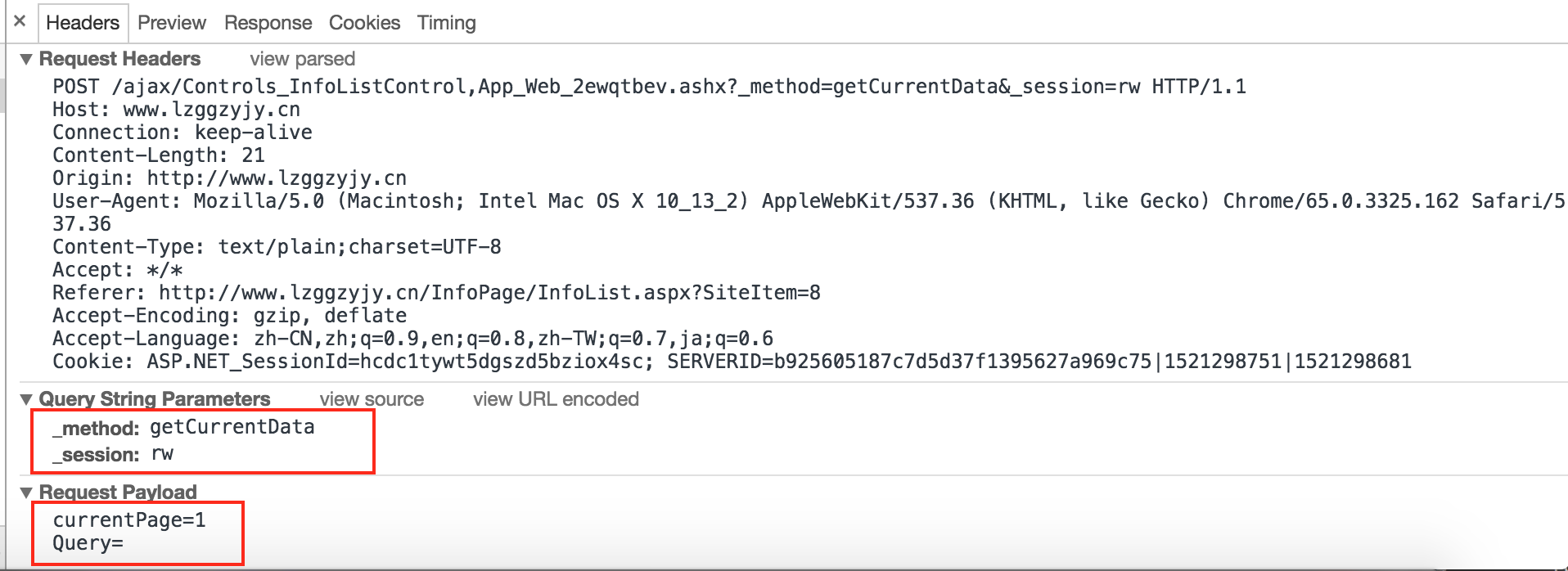
我把代码贴上来:
#! /usr/bin/env python3
# -*- coding:utf-8 –*-
import requests
import json
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def testDownloadLanZhou():
testUrl = 'http://www.lzggzyjy.cn/ajax/Controls_InfoListControl,App_Web_2ewqtbev.ashx?_method=getCurrentData&_session=rw'
testHeaders = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36',
'Host':'www.lzggzyjy.cn',
'Referer':'http://www.lzggzyjy.cn/InfoPage/InfoList.aspx?SiteItem=8',
'X-Requested-With':'XMLHttpRequest',
# "Content-Type":'text/plain;charset=UTF-8',
"Cookie":'ASP.NET_SessionId=hcdc1tywt5dgszd5bziox4sc; SERVERID=b925605187c7d5d37f1395627a969c75|1521298751|1521298681'
}
# testParams = {'_method':'getCurrentData', '_session':'rw'}
testData = {'currentPage':'1', 'Query':''}
# 将dic 转换成json字符串
# jsonDataString = json.dumps(testData)
# print(jsonDataString)
# print(type(jsonDataString))
# # 对应每个参数添加换行隔开
# newString = jsonDataString.replace(',', '\n')
# print(newString)
resq = requests.post(testUrl, headers=testHeaders, data=testData)
print(resq.content)
这个请求怎么弄都不对,获取不到正确的html页面......请各位指点迷津




