hive可以正常使用,切换成impal时可以读取到hive库表元数据,单数读取不到标的字段信息,查询时就报错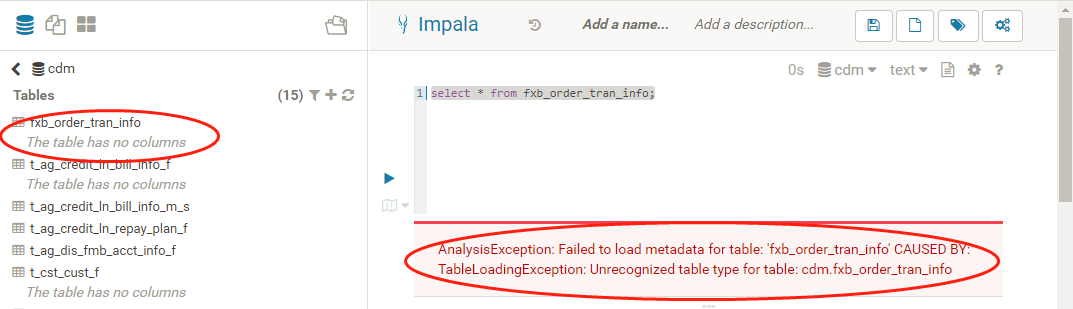
请教各位大神,又遇到过类似问题么?

impala读取hive元数据问题

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新

- 2021-12-19 11:35回答 2 已采纳 查了一些资料,Datax源码的确有点问题,需要修改Datax的源码。参考: datax mysql null不能转为Long 等一些列无法强转问题_大壮的博客-CSDN博
- 2018-04-24 10:01回答 2 已采纳 impala启动 # service impala-state-store start # service impala-catalog start # service impala-serve
- 2022-03-19 18:44回答 2 已采纳 为啥你的连接, port 是21050 不是 8091是网络管理员重新定向了?
- 2021-01-17 20:27大数据面壁者的博客 使用JDBC的方式直接去mysql中读取元数据,称为直连模式 需要的条件: 连接Mysql的驱动,已经放入到$HIVE_HOME/lib下 创建连接时,需要有url,username,password,driveClassName,在hive-site.xml中配置 <property...
- 2021-12-06 16:26回答 1 已采纳 会出现报错信息的
- 2018-05-31 01:35回答 2 已采纳 先确认下 A表和B表的定义。 show create table A; show create table B; 看下两个表的定义是否完全一致,另外看下 insert 语句是否按照 表的各个字段
- 2022-03-24 19:22回答 1 已采纳 加一行代码,把 arraysize 设置成 1 try: conn = connect(host=hive_host, port=hive_port, database=hive_databa
- 2022-04-16 00:53大数据老司机的博客 文章目录一、概述 一、概述 Impala的服务端是一个分布式的、大规模并行处理(MPP:Massively ...不像hive,impala的服务端天然就是分布式的,在架构层面上,它在安装时就会跟DN计算节点放在一起。Impala官方文档 ...
- 2018-01-16 02:35回答 2 已采纳 最后一个图,那个域名和端口连不上,要么是网络问题(国外网站特别如此,你懂的),要么是服务器地址或者端口无效。
- 2017-04-26 03:31回答 2 已采纳 pip install thrift==0.9.3 不谢
- 2022-08-05 14:31回答 2 已采纳 是的,基本就是离线数仓的岗位了
- 2019-03-19 13:01Ego_Bai的博客 Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。 ...
- 2018-05-03 02:34回答 3 已采纳 票据有过期时间的 设置crontab 定期去刷新就好了。或者你把过期时间设置很大
- 2022-12-13 10:44安博里阿的博客 INVALIDATE METADATA操作带来的副作用是生成一个新的未完成的元数据对象,对于操作请求的impalad(称它为impalad-A),能够立马获取到该对象,对于其它的impalad必须通过statestored同步,执行完该操作,因此处理该...
- 2020-06-03 14:58AllenGd的博客 大数据领域里面,实时分析(在线查询)系统是最常见的一种场景,通常用于客户投诉处理,实时数据分析,在线查询等等过。因为是查询应用,通常有以下特点: a. 时延低(秒级别)。 b. 查询条件复杂(多个维度,维度...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 素材场景中光线烘焙后灯光失效
- ¥15 请教一下各位,为什么我这个没有实现模拟点击
- ¥15 执行 virtuoso 命令后,界面没有,cadence 启动不起来
- ¥50 comfyui下连接animatediff节点生成视频质量非常差的原因
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题
- ¥15 slam rangenet++配置
- ¥15 有没有研究水声通信方面的帮我改俩matlab代码
- ¥15 ubuntu子系统密码忘记
- ¥15 保护模式-系统加载-段寄存器