

需要获取机场航班数据
该机场的url地址https://zh.flightaware.com/live/airport/KHRL
其航班数据是动态加载进来的,通过F12并刷新后得到
https://zh.flightaware.com/ajax/ignoreall/trackpoll.rvt?token=c35ca45ecbca57cd1ea443d1c65c36426ea06630de026ffd737977e4a40a26ead614b3f2ddde9907453c214a859f7965-88dd7c1a0d41355dafa2ce4ff0e607704b11c422c13281778f5b552d40a619d4c5559546eb9966e7-501878875ac23bacc59c19453f7939a79b200f0e&locale=zh_CN&summary=0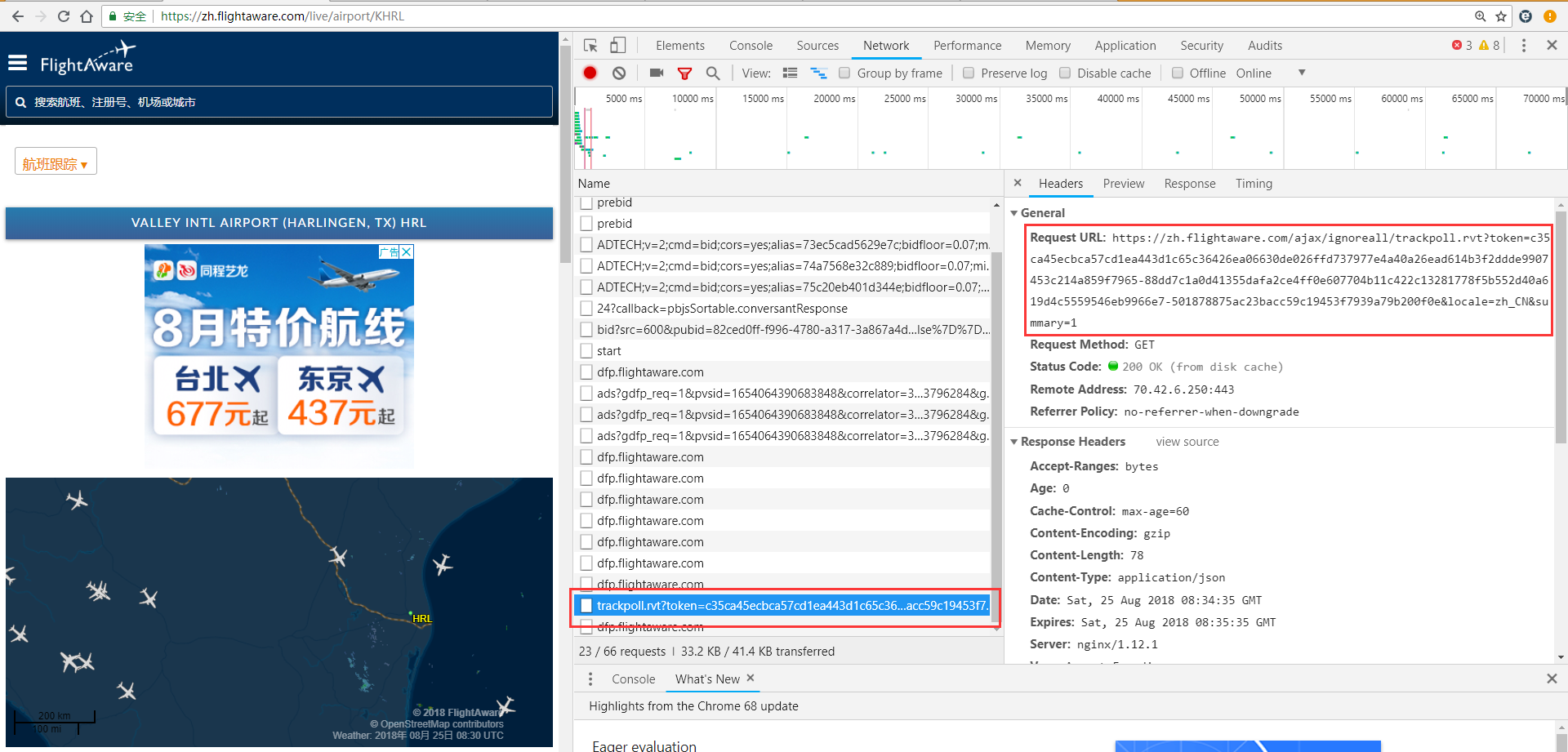
现在的问题是我有数千个机场的url地址,手动F12找到每个机场的航班地址是无法想象的,所以有没有方法自动获得每个机场请求航班数据的那个URL?
万望大神有空瞅瞅!感谢!





