公司服务器部署在windows系统下,电脑上安装flume,查看版本的时候,运行失败,求解决方案!
hadoop、jdk等均配置完成。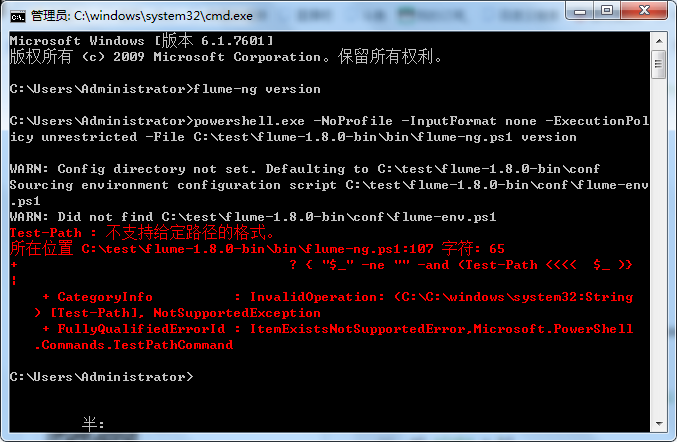
问题已解决,将其中flume-env.ps1的关于gethadoop,gethbase,以及gethive等相关代码注释掉之后就可以正常使用了!

公司服务器部署在windows系统下,电脑上安装flume,查看版本的时候,运行失败,求解决方案!
hadoop、jdk等均配置完成。
问题已解决,将其中flume-env.ps1的关于gethadoop,gethbase,以及gethive等相关代码注释掉之后就可以正常使用了!
 分享
分享 将其中flume-env.ps1的关于gethadoop,gethbase,以及gethive等相关代码注释掉
分享

