想从PDF中提取文本,并整理成阅读顺序,求一个好的提取方法,或者好的整理方法,尤其是分栏的PDF文件,求大佬指点

python3如何按阅读顺序从PDF文件中提取文本,或者如何整理成阅读的顺序?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 AI算法爱好者角落 2021-01-29 15:53关注
AI算法爱好者角落 2021-01-29 15:53关注import pyocr import importlib import sys import time importlib.reload(sys) time1 = time.time() # print("初始时间为:",time1) import os.path from pdfminer.pdfparser import PDFParser,PDFDocument from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import PDFPageAggregator from pdfminer.layout import LTTextBoxHorizontal,LAParams from pdfminer.pdfinterp import PDFTextExtractionNotAllowed text_path = r'words-words.pdf' # text_path = r'photo-words.pdf' def parse(): '''解析PDF文本,并保存到TXT文件中''' fp = open(text_path,'rb') #用文件对象创建一个PDF文档分析器 parser = PDFParser(fp) #创建一个PDF文档 doc = PDFDocument() #连接分析器,与文档对象 parser.set_document(doc) doc.set_parser(parser) #提供初始化密码,如果没有密码,就创建一个空的字符串 doc.initialize() #检测文档是否提供txt转换,不提供就忽略 if not doc.is_extractable: raise PDFTextExtractionNotAllowed else: #创建PDF,资源管理器,来共享资源 rsrcmgr = PDFResourceManager() #创建一个PDF设备对象 laparams = LAParams() device = PDFPageAggregator(rsrcmgr,laparams=laparams) #创建一个PDF解释其对象 interpreter = PDFPageInterpreter(rsrcmgr,device) #循环遍历列表,每次处理一个page内容 # doc.get_pages() 获取page列表 for page in doc.get_pages(): interpreter.process_page(page) #接受该页面的LTPage对象 layout = device.get_result() # 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 # 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 # 想要获取文本就获得对象的text属性, for x in layout: if(isinstance(x,LTTextBoxHorizontal)): with open(r'2.txt','a') as f: results = x.get_text() print(results) f.write(results +"\n") if __name__ == '__main__': parse() time2 = time.time() print("总共消耗时间为:",time2-time1)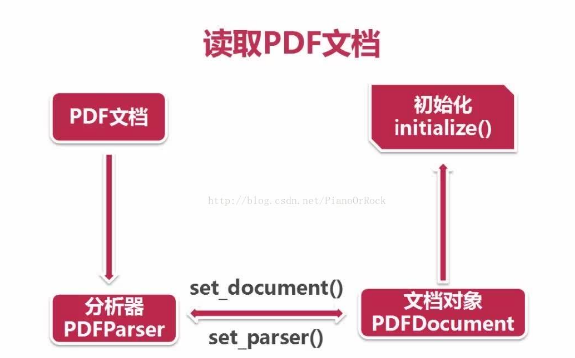 解决评论 打赏无用 1举报 分享
解决评论 打赏无用 1举报 分享
- 2025-10-19 21:48猫头虎的博客 Python提取PDF内容全攻略 本文详细...Camelot(推荐)或tabula-py OCR扫描件:OCRmyPDF一站式方案 核心代码示例 三行提取文本(pypdf) 精细控制布局(pdfminer.six) 表格识别导出CSV(Camelot) 进阶应用 扫描件OCR
- 2024-06-17 17:01岳涛@泰山医院的博客 PyMuPDF Ver 1.24.4 操作手册 - 01 从PDF中提取文本
- 2025-02-06 14:21塞大花的博客 前文介绍了PyMuPDF基本的安装和基础的功能,本文将详细介绍PyMuPDF处理PDF(和其他)文档的打开文件和文本处理功能。
- 2025-08-06 19:25数据知道的博客 本文介绍了将英文PDF翻译为中文的有效方法。在线翻译服务(如Google、DeepL)操作简单但格式易错乱,适合快速获取大意;专业软件(如Trados、OmegaT)能较好保留格式且质量高,但需学习成本;编程脚本(基于Python)...
- 2023-09-27 14:11艾派森的博客 因工作中的某些奇葩要求,需要将PDF文件的每页内容转存成按顺序编号的图片。用第三方软件或者在线转换也可以,但批量操作还是Python方便,所谓搞定办公自动化,Python出山,一统天下;Python出征,寸草不生~ O(∩_∩...
- 2025-02-11 14:31塞大花的博客 MinerU是一款将PDF转化为机器可读格式的工具(如markdown、json),可以很方便地抽取为任意格式。本文介绍了运行MinerU项目的基本方法实践过程,后面会进一步分析和走读MinerU项目的源码。
- 2025-06-18 17:36佑瞻的博客 通过今天的分享,我们系统学习了 LangChain 处理 PDF 的全流程方案:从最简单的文本提取,到向量索引构建;从复杂布局分析,到多模态直接处理。简单文本提取:优先使用 PyPDFLoader,轻量高效问答系统:PyPDFLoader ...
- 2020-11-17 17:19weixin_39917046的博客 PDF文档处理工作中,总是绕不开对文本提取的需求。很多用户觉得我们PDFlux好用,所以对其中的底层技术也非常感兴趣。也有人为认为,从PDF里抽取文本段落和表格,应该非常简单!近期,我们会对PDF文档的前世今生和...
- 2025-04-07 13:24AI小胖的博客 通过 pdfplumber.open() 解析复杂PDF:
- 2025-01-17 15:53塞大花的博客 PDF是一种日常工作中广泛使用的跨平台文档格式,常常包含丰富的内容:包括文本、图表、表格、公式、图像。在现代信息处理工作流中发挥了重要的作用,尤其是RAG项目中,通过将非结构化数据转化为结构化和可访问的信息...
- 没有解决我的问题, 去提问
