自己写了一个爬代码,可以通过改变参数来爬取不同的内容,现在想给他添加一个gui界面,用按钮点击运行怎么办
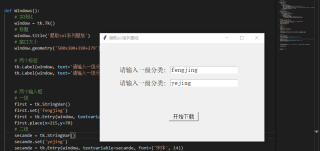
图形画好了
爬虫代码也准备好了
from lxml import etree
import requests
import os
import threading
import queue
from urllib import parse
import time
import tkinter as tk
# from tkinter import *
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'cookie':'HMACCOUNT_BFESS=5A76C20AA8660D57; BDUSS_BFESS=UwZTVlQ0oxdTNNcVRiUUp3YkZ2YlpTWEtMN2tNSFpFeWdRUlRjRDlxZTBobDFmRVFBQUFBJCQAAAAAAAAAAAEAAAD8Ar-O70yDuv2XAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALT5NV-0-TVfYj; BDSFRCVID_BFESS=dPCOJeC62xqMEQoeDjW8TGYSv07fn5jTH6aocB2aoVUNToy-YSWMEG0PDM8g0Kubo25nogKKBeOTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tR-JoDDMJDL3qPTuKITaKDCShUFsKpOmB2Q-5KL-MPjYsfjvbfO83Tk7Qnrg-j8f5D_tBfbdJJjoHp_4-tn43fC7hpuLXlJUBmTxoUJgBCnJhhvG-4PKjtCebPRi3tQ9Qg-qahQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0HPonHj8he5bP; BAIDUID_BFESS=7C613C37D1AFB222B605AA8CCBB44540:FG=1',
}
# 使用代理
proxy = {
'http':'113.194.143.101:9999'
}
# 获取夜景壁纸列表,返回每个图组的urls
def yejing_pic_list(base_url):
res = requests.get(base_url,proxies=proxy,headers=headers).content.decode('gbk')
html = etree.HTML(res)
Incomplete_url = html.xpath('//li[@class="photo-list-padding"]/a/@href') # 返回的是['/bizhi/8139_101249_2.html', '/bizhi/7947_98766_2.html', '/bizhi/7741_96199_2.html', '/bizhi/7568_93902_2.html', '/bizhi/7203_89142_2.html', '/bizhi/7000_86950_2.html', '/bizhi/6704_83622_2.html', '/bizhi/6383_78552_2.html', '/bizhi/6062_75033_2.html']
s = 'https://desk.zol.com.cn'
global name
name = html.xpath('//li[@class="photo-list-padding"]/a/span/em/text()') # 返回的是['繁华的都市唯美夜景壁纸', '城市图片-城市夜景壁纸图', '瑰丽的城市夜景壁纸', '都市夜景犹如漫画游戏般梦', '古城夜景桌面壁纸', '厦门夜景桌面壁纸', '2016年Bing夜景主题桌面壁', '高空视角城市夜景桌面壁纸', '唯美夜景图片-唯美夜景图']
# 拼接url s+Incomplete_url
for i in range(len(Incomplete_url)):
Incomplete_url[i] = s + Incomplete_url[i]
urls_list = Incomplete_url # 返回的是['https://desk.zol.com.cn/bizhi/8139_101249_2.html', 'https://desk.zol.com.cn/bizhi/7947_98766_2.html', 'https://desk.zol.com.cn/bizhi/7741_96199_2.html', 'https://desk.zol.com.cn/bizhi/7568_93902_2.html', 'https://desk.zol.com.cn/bizhi/7203_89142_2.html', 'https://desk.zol.com.cn/bizhi/7000_86950_2.html', 'https://desk.zol.com.cn/bizhi/6704_83622_2.html', 'https://desk.zol.com.cn/bizhi/6383_78552_2.html', 'https://desk.zol.com.cn/bizhi/6062_75033_2.html']
return name,urls_list
# 返回每张图的网页链接
def secande(urls_list):
list_1 = []
for x in urls_list:
resp = requests.get(x,headers=headers).content.decode('gbk')
html = etree.HTML(resp)
links = html.xpath('//div[@class="photo-list-box"]/ul//li/a/@href')
s = 'https://desk.zol.com.cn'
url_links = [s+i for i in links]
list_1.append(url_links)
return list_1
# 返回每张图片的真实链接
def new_links(list_1):
url_111 = []
for i in list_1:
# print('='*220)
url_111_dict={}
for index,y in enumerate(i):
resp = requests.get(y,headers=headers).content.decode('gbk')
html_1 = etree.HTML(resp)
adress = html_1.xpath('//div[@id="mouscroll"]/img/@src')[0].replace('t_s960x600c5','t_s1920x1080')
url_111_dict[f'img_No.{index+1}']=adress
url_111.append(url_111_dict)
# print(url_111)
return url_111
def hebing(name,url_111):
for n,u in zip(name,url_111):
print(n,u)
path = os.path.join('zol高清壁纸',n)
if not os.path.exists(path):
os.mkdir(path)
for img_links in u.items():
index,img_links = img_links
with open(os.path.join(path, f'{index}.jpg'),'wb') as fp:
fp.write(requests.get(img_links,headers=headers).content)
def main():
f = input('请输入壁纸一级分类:')
s = input('请输入壁纸二级分类:')
base_url = 'https://desk.zol.com.cn/{one}/{tow}/'.format(one=f,tow=s)
name,urls_list = yejing_pic_list(base_url)
list_1 = secande(urls_list)
url_111 = new_links(list_1)
hebing(name,url_111)
def Windows():
# 实例化
window = tk.Tk()
# 标题
window.title('爬取zol系列壁纸')
# 窗口大小
window.geometry('500x300+398+279')
# 两个标签
tk.Label(window, text='请输入一级分类:', font=('宋体', 14)).place(x=57, y=70)
tk.Label(window, text='请输入一级分类:', font=('宋体', 14)).place(x=57, y=110)
# 两个输入框
# 一级
first = tk.StringVar()
first.set('fengjing')
first = tk.Entry(window, textvariable=first, font=('宋体', 14))
first.place(x=215,y=70)
# 二级
secande = tk.StringVar()
secande.set('yejing')
secande = tk.Entry(window, textvariable=secande, font=('宋体', 14))
secande.place(x=215,y=110)
# 按钮
b = tk.Button(window, text='开始下载', font=('宋体', 12), width=10, height=1, command=main)
b.place(x=210,y=210)
window.mainloop()
if __name__=='__main__':
Windows()
这个是画好的图形,想通过两个文本框收集到的参数传递给main函数里面的base_url,点击开始下载,完成爬虫的运行工作
这该怎么弄啊