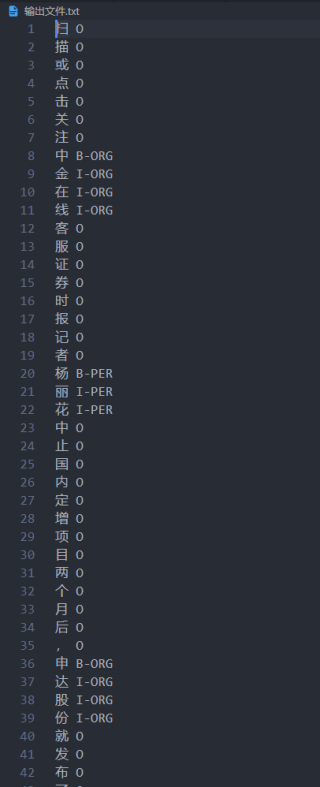
读入train文件,文件已经经过BIO标记,格式为text label。
train文件内容如下所示(句中每个字间由空格隔开,text与label之间由若干空格组成,且每句话中text与label间的空格数不固定,每句话‘text+label’占一行):
扫 描 或 点 击 关 注 中 金 在 线 客 服 证 券 时 报 记 者 杨 丽 花 中 止 国 内 定 增 项 目 两 个 月 后 , 申 达 股 份 就 发 布 了 新 的 非 公 开 发 行 预 案 。 O O O O O O O B-ORG I-ORG I-ORG I-ORG O O O O O O O O B-PER I-PER I-PER O O O O O O O O O O O O O B-ORG I-ORG I-ORG I-ORG O O O O O O O O O O O O O O
根 据 《 2 0 1 7 年 非 公 开 发 行 A 股 股 票 预 案 》 称 , 拟 向 包 括 公 司 控 股 股 东 申 达 集 团 在 内 的 不 超 过 1 0 名 ( 含 1 0 名 ) 特 定 投 资 者 非 公 开 发 行 A 股 股 票 数 量 不 超 过 1 4 , 2 0 4 . 8 5 万 股 , 其 中 申 达 集 团 认 购 股 票 数 量 为 本 次 发 行 股 票 总 量 的 3 1 . 0 7 % , 募 集 资 金 总 额 不 超 过 2 1 . 5 6 亿 元 ( 含 发 行 费 用 ) , 募 集 资 金 扣 除 发 行 相 关 费 用 后 将 用 于 收 购 I A C 集 团 之 S T & A 业 务 相 关 资 产 , I A C 集 团 拟 将 上 述 资 产 注 入 新 设 的 A u r i a 公 司 , 由 申 达 股 份 通 过 申 达 英 国 公 司 认 购 A u r i a 公 司 7 0 % 的 股 份 。 O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O B-ORG I-ORG I-ORG I-ORG O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O B-ORG I-ORG I-ORG I-ORG O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O B-ORG I-ORG I-ORG I-ORG I-ORG O O O O O O O O O O O O B-ORG I-ORG I-ORG I-ORG I-ORG O O O O O O O O O O O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG O O B-ORG I-ORG I-ORG I-ORG O O O O B-ORG I-ORG I-ORG I-ORG O O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG O O O O O O O
将其转换为
扫 O
描 O
或 O
点 O
击 O
关 O
注 O
中 B-ORG
金 I-ORG
在 I-ORG
线 I-ORG
……
的格式(每行由一个字和一个标签组成,字与标签中间由空格隔开,字和标签的对应方式是每句话中‘字’的相应位置(第几个)与句子后跟的‘标签’的位置(第几个)对应,句与句之间用空行间隔),将转换后的结果保存到文件。