import time
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append("..")
from d2l import torch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(torch.__version__)
print(device)
def batch_norm(is_training, X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 判断当前模式是训练模式还是预测模式
if not is_training:
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。这里我们需要保持
# X的形状以便后面可以做广播运算
mean = X.mean(dim=0, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
var = ((X - mean) ** 2).mean(dim=0, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
# 训练模式下用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 拉伸和偏移
return Y, moving_mean, moving_var
class BatchNorm(nn.Module):
def __init__(self, num_features, num_dims):
super(BatchNorm, self).__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成0和1
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 不参与求梯度和迭代的变量,全在内存上初始化成0
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.zeros(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var, Module实例的traning属性默认为true, 调用.eval()后设成false
Y, self.moving_mean, self.moving_var = batch_norm(self.training,
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
net = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels, kernel_size
BatchNorm(6, num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
BatchNorm(16, num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
d2l.FlattenLayer(),
nn.Linear(16*4*4, 120),
BatchNorm(120, num_dims=2),
nn.Sigmoid(),
nn.Linear(120, 84),
BatchNorm(84, num_dims=2),
nn.Sigmoid(),
nn.Linear(84, 10)
)
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
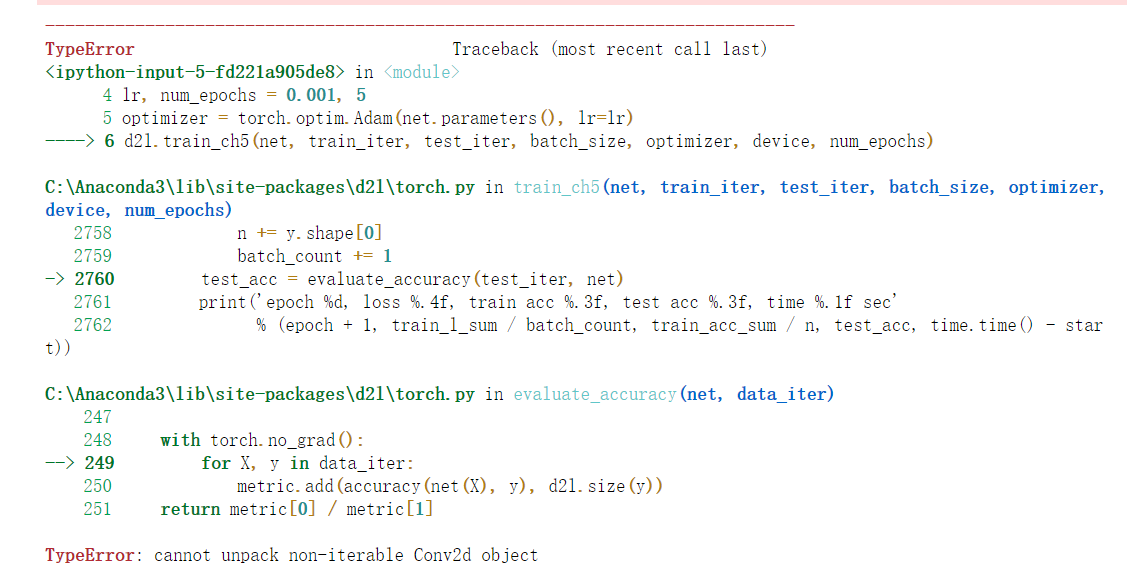
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs
########运行后错误提示
TypeError Traceback (most recent call last)
<ipython-input-5-fd221a905de8> in <module>
4 lr, num_epochs = 0.001, 5
5 optimizer = torch.optim.Adam(net.parameters(), lr=lr)
----> 6 d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
C:\Anaconda3\lib\site-packages\d2l\torch.py in train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
2758 n += y.shape[0]
2759 batch_count += 1
-> 2760 test_acc = evaluate_accuracy(test_iter, net)
2761 print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
2762 % (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
C:\Anaconda3\lib\site-packages\d2l\torch.py in evaluate_accuracy(net, data_iter)
247
248 with torch.no_grad():
--> 249 for X, y in data_iter:
250 metric.add(accuracy(net(X), y), d2l.size(y))
251 return metric[0] / metric[1]
TypeError: cannot unpack non-iterable Conv2d object

cannot unpack non-iterable Conv2d object,出现这个错误提示

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 天夏Ai 2023-04-11 15:06关注
天夏Ai 2023-04-11 15:06关注"cannot unpack non-iterable Conv2d object"错误提示通常表示您在使用PyTorch等深度学习框架时,试图对一个非可迭代的Conv2d对象进行解包操作。
在PyTorch中,Conv2d是一种常用的卷积层类型,它可以接收输入张量并将其卷积成输出张量。通常情况下,您需要在模型中定义Conv2d层的参数(如输入通道数、输出通道数、卷积核大小等),然后将它们传递给Conv2d对象来创建该层。
如果您尝试对一个已经创建的Conv2d对象进行解包操作,则会出现上述错误提示。为了解决这个问题,您需要检查代码中是否存在对Conv2d对象的不当解包操作。可能的解决方法包括:
1、检查代码中的解包语句:查找代码中对Conv2d对象的解包操作,确保它们使用正确的语法和参数。例如,如果您使用的是Python3,可以使用星号运算符(*)将Conv2d对象打包成元组或列表。示例代码如下:
```python import torch.nn as nn # 定义一个Conv2d层 conv = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1) # 正确的解包方式 x = torch.randn(1, 3, 224, 224) out = conv(x) out, = out # 使用星号运算符将输出张量打包成元组,然后再解包 # 错误的解包方式 out = conv(x) a, b = out # 直接对Conv2d对象进行解包会导致错误提示```
1、检查输入参数的类型:确保您将正确类型的张量作为Conv2d层的输入参数。例如,Conv2d层期望的输入张量是四维的,如果您传递了一个三维或二维的张量,则会出现错误提示。2、检查框架版本:如果您使用的是较旧版本的PyTorch或其他深度学习框架,可能需要升级到最新版本以避免此类错误。可以尝试更新框架版本并重新运行代码。
希望这些建议能够帮助您解决问题。
解决 无用评论 打赏举报 分享
- 2022-01-19 10:49北北的喵有点甜的博客 Tensorflow2.7.0:学习Tensorflow过程中对语法的不熟悉易导致报错,本文章记录一些在Tensorflow2.7.0下的错误,官方文档可以自行查看。
- 2025-05-10 12:44E的工程笔记的博客 当每个进程使用多个GPU时,这会影响torch.nn.DataParallel和torch.nn.parallel.DistributedDataParallel的行为(参见多GPU工作指南)。 参数说明 device_type (str, 必填) – 指定使用的设备类型。可选值包括:...
- 2023-09-13 08:22weixin_48228856的博客 每个动作类别的文件夹我放了100个视频,视频长度都是5~6s。 三、搭建openpose环境 因为在运行stgcn之前有用到,参考如下。 openpose环境搭建(详细教程CPU/GPU)windows 10+python 3.7+CUDA 11.6+VS2022_openpose...
- 2023-05-13 19:39空持千百偈,不如吃茶去的博客 安装OpenPCDet次数较多,总结出的一些错误。
- 2024-08-20 23:42囚生CY的博客 序言 last, but not the last 终于也走到了这一步。 文章目录 序言 20240820 20240821~20240823 20240824 20240825 20240826 20240827 20240828 20240829 20240830 20240831 20240901 20240902 20240903 20240904 ...
- 2022-08-30 19:25Wanderer001的博客 Recurrent layers RNN LSTM GRU RNNCell LSTMCell GRUCell Transformer ...2d Dropout3d AlphaDropout Sparse layers Embedding EmbeddingBag Distance functions CosineSimilarity PairwiseDistance Loss functions ...
- 2016-06-08 21:34weixin_34408717的博客 "object": "python::object", "float": "double"} if type_name in alias: return alias[type_name] if type_name in value_types(): return type_name ma = re.compile(r"vector<(.*)>").match(type_name) ...
- 2024-07-05 11:11绝不原创的飞龙的博客 Zip64 # 创建并返回一个 ZipFile 对象,传入 file、args 和 kwargs return zipfile.ZipFile(file, *args, **kwargs) # 设置模块名称为'numpy.lib.npyio',用于标识这个类所属的模块 @set_module('numpy.lib.npyio') ...
- 没有解决我的问题, 去提问
