我2千万数字排序用pyspark,spark standalone模式跑的,用的算子sortbykey,服务器分别是32g,32核剩余15g,一个是8g剩余1g,4核。排序用时7s多,感觉用时太多,我不知道到底是那方面问题,求解惑。
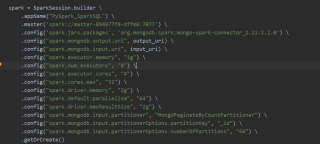

我2千万数字排序用pyspark,spark standalone模式跑的,用的算子sortbykey,服务器分别是32g,32核剩余15g,一个是8g剩余1g,4核。排序用时7s多,感觉用时太多,我不知道到底是那方面问题,求解惑。
 分享
分享
你这是从mongodb把数读取出来然后再排序的么?可以看下取数的耗时。然后再spark webui上看看stage的时间消耗在什么地方了
分享 已采纳回答
7月9日
创建了问题
7月9日
已采纳回答
7月9日
创建了问题
7月9日


