
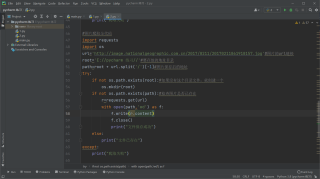
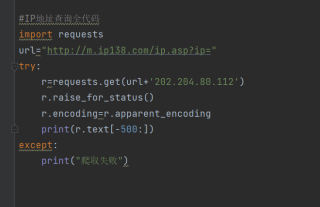
按照慕课网爬虫视频的代码编写的,图片爬取和保存,IP地址获取的代码都和嵩天teacher的代码一致,却爬取失败
实在找不出原因了

按照慕课网爬虫视频的代码编写的,图片爬取和保存,IP地址获取的代码都和嵩天teacher的代码一致,却爬取失败
实在找不出原因了
 分享
分享
 关注
关注爬虫被封禁常见原因列表
如果你一直被网站封杀却找不到原因,那么这里有个检查列表,可以帮你诊断一下问题出在哪里。
首先,检查 JavaScript 。如果你从网络服务器收到的页面是空白的,缺少信息,或其遇到他不符合你预期的情况(或者不是你在浏览器上看到的内容),有可能是因为网站创建页面的 JavaScript 执行有问题。
检查正常浏览器提交的参数。如果你准备向网站提交表单或发出 POST 请求,记得检查一下页面的内容,看看你想提交的每个字段是不是都已经填好,而且格式也正确。用 Chrome 浏览器的网络面板(快捷键 F12 打开开发者控制台,然后点击“Network”即可看到)查看发送到网站的 POST 命令,确认你的每个参数都是正确的。
是否有合法的 Cookie?如果你已经登录网站却不能保持登录状态,或者网站上出现了其他的“登录状态”异常,请检查你的 cookie。确认在加载每个页面时 cookie 都被正确调用,而且你的 cookie 在每次发起请求时都发送到了网站上。
IP 被封禁?如果你在客户端遇到了 HTTP 错误,尤其是 403 禁止访问错误,这可能说明网站已经把你的 IP 当作机器人了,不再接受你的任何请求。你要么等待你的 IP 地址从网站黑名单里移除,要么就换个 IP 地址(可以去星巴克上网)。如果你确定自己并没有被封杀,那么再检查下面的内容。
确认你的爬虫在网站上的速度不是特别快。快速采集是一种恶习,会对网管的服务器造成沉重的负担,还会让你陷入违法境地,也是 IP 被网站列入黑名单的首要原因。给你的爬虫增加延迟,让它们在夜深人静的时候运行。切记:匆匆忙忙写程序或收集数据都是拙劣项目管理的表现;应该提前做好计划,避免临阵慌乱。
还有一件必须做的事情:修改你的请求头!有些网站会封杀任何声称自己是爬虫的访问者。如果你不确定请求头的值怎样才算合适,就用你自己浏览器的请求头吧。
确认你没有点击或访问任何人类用户通常不能点击或接入的信息。
如果你用了一大堆复杂的手段才接入网站,考虑联系一下网管吧,告诉他们你的目的。试试发邮件到 webmaster@< 域名 > 或 admin@< 域名 >,请求网管允许你使用爬虫采集数据。管理员也是人嘛!
 已采纳回答
7月20日
创建了问题
7月20日
已采纳回答
7月20日
创建了问题
7月20日




