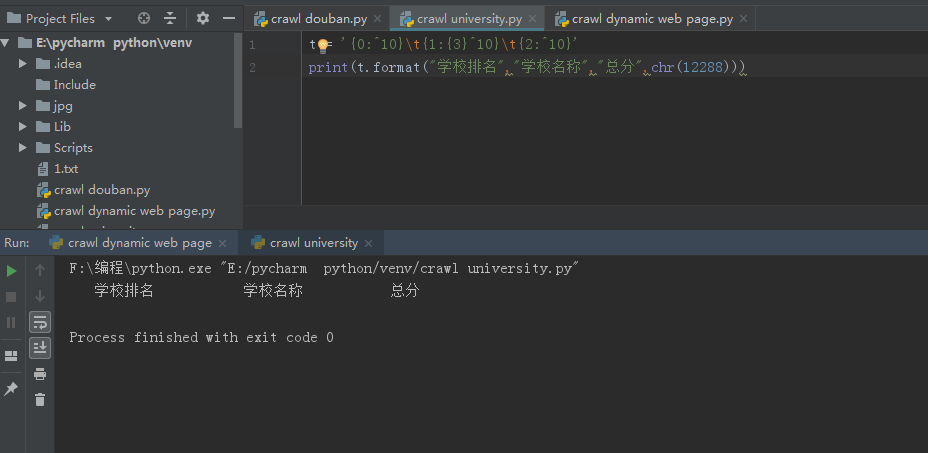
这是在网课上看到的一段代码,后面的chr(12288)用来当作空格填充进去,不太理解。chr()函数不是只能表示0-256之间的数字吗?这里为什么可以这么用
收起
要看你的python是什么版本的, http://www.runoob.com/python3/python3-func-chr-html.html
报告相同问题?

 分享 分享
分享 分享
