
问题如题
SELECT
COUNT(1)
FROM
wf_workitem a -- 总数量159521
JOIN wf_activityinst b ON b.id = a.activityinst_id -- 总数量209453
JOIN wf_processinst c ON c.id = b.processinst_id -- 总数量26307
WHERE
a.operate_user = '7424'
AND a.current_state = 'AGREE'
AND c.comp_id = '4715C67AD2B0457A81D32CC0B1148840'
AND c.proj_id = ''
解析计划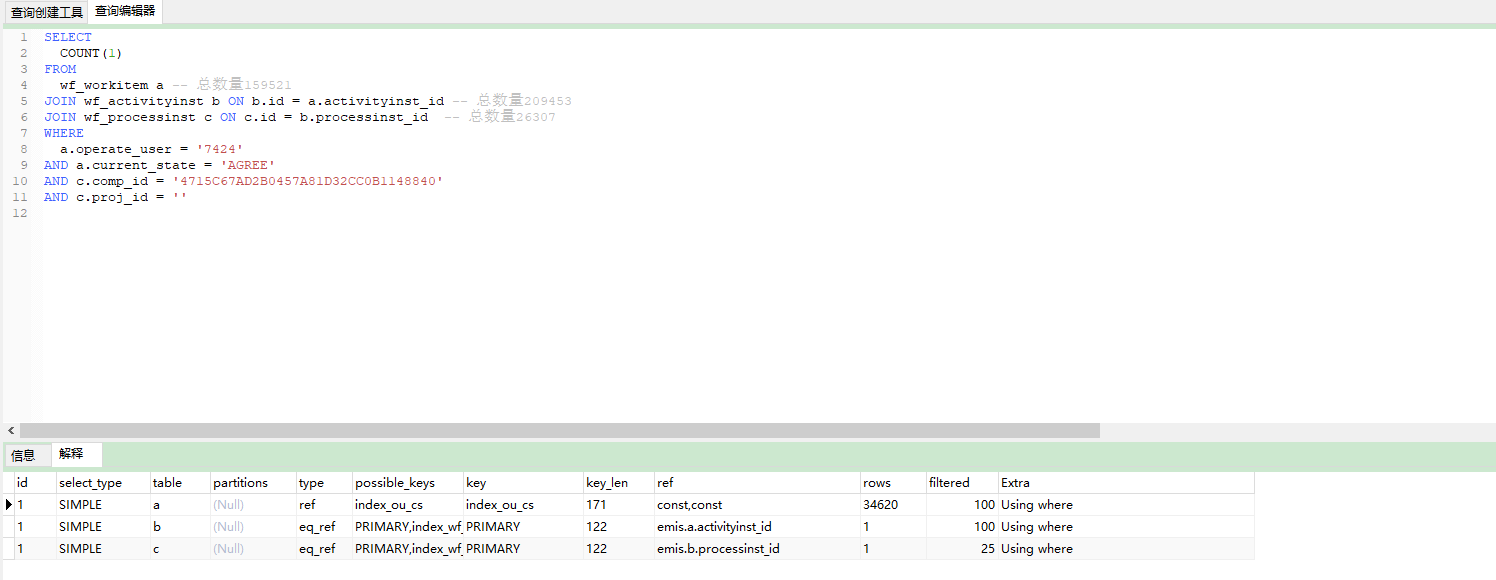
sql执行需要10s左右, 求给点优化建议





