

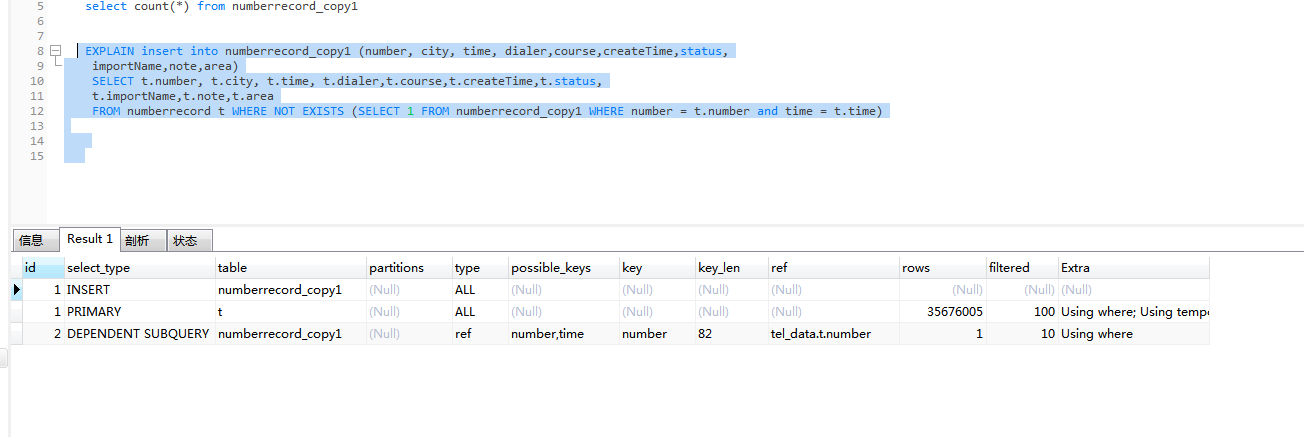
如图:numberrecord 表 3600W数据量。
需求是去重掉 time 与 number一致的数据。 我用的去重插入复制表的方法。
目前已经执行12个小时了,一夜没睡。
试过用java去处理,多线程分页查询去重,jvm直接崩溃。 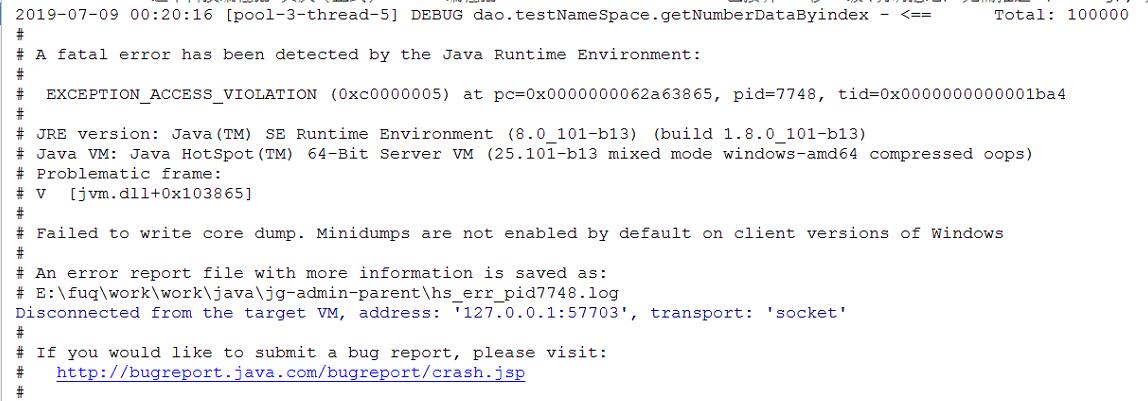
VM options : -Xms5000m -Xmx8000m 电脑内存16G的
问题2就是3600W数据
SELECT number FROM numberrecord where time <'2019-07-08' group by number
需要查询出 2019-07-08之前的所有number数据. 这个sql 如何优化。
time,number都有索引
求大牛给个高效率解决方案。



