
DQN中误差计算是由上式的均方误差来定义的,我的神经网络的输出是Qeval,是Action个q值,但是我在用tensenflow代码实现max(Q(snext)) 时遇到了问题,就是我有两个版本
版本一用one-hot编码动作,然后用动作和Qeval向量相乘的到max(Q(snext))
版本二没有使用动作,直接用tf.reduce mean(Qeval,axis=1)来直接得到max(Q(snext))。
那么问题来了:(每训练100步,然后再测试十次取平均,使用的gym.cartPole-v0环境)我用版本一,大约第1100回合就可以达到200分。
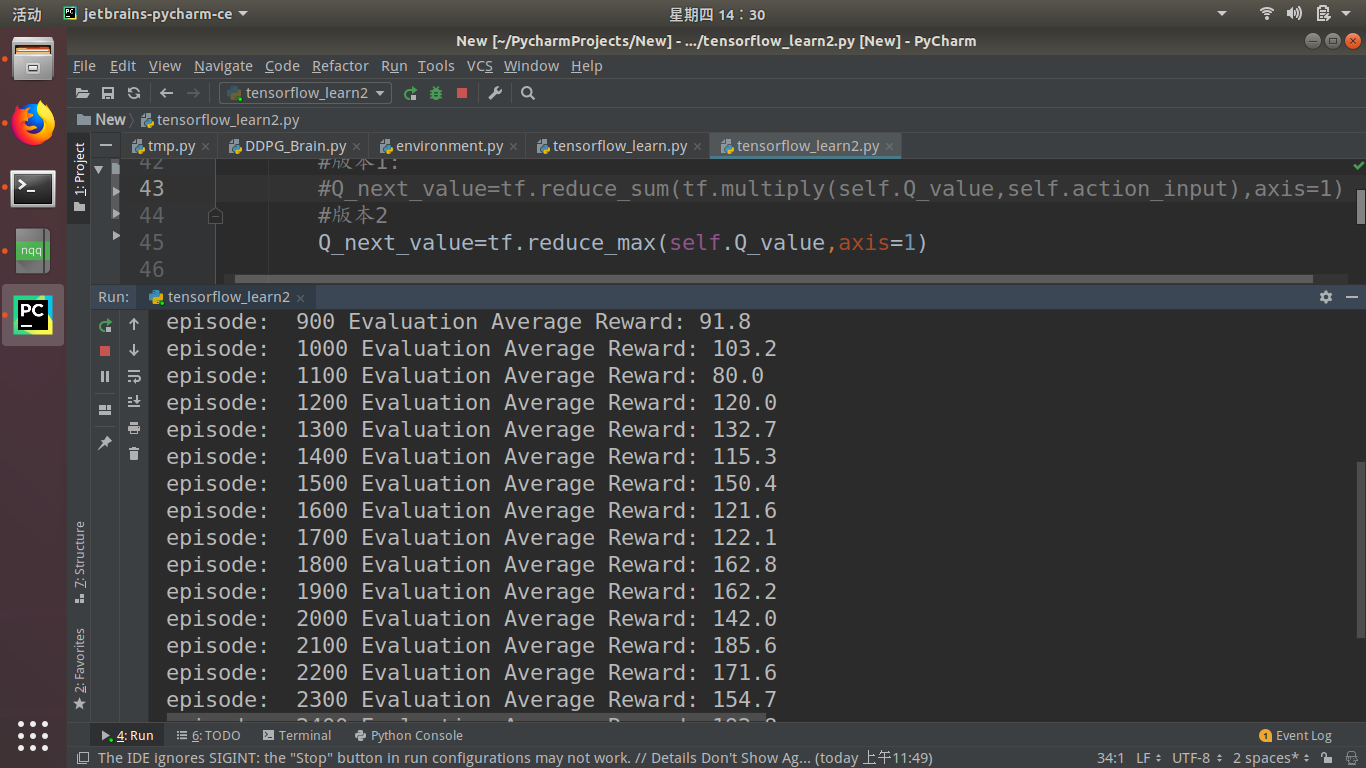
我用版本二,效果却相差有点大。我想问:这两个版本的计算效果都是一样的,可为什么效果却差很多呢(运行了多次,结果都一样)?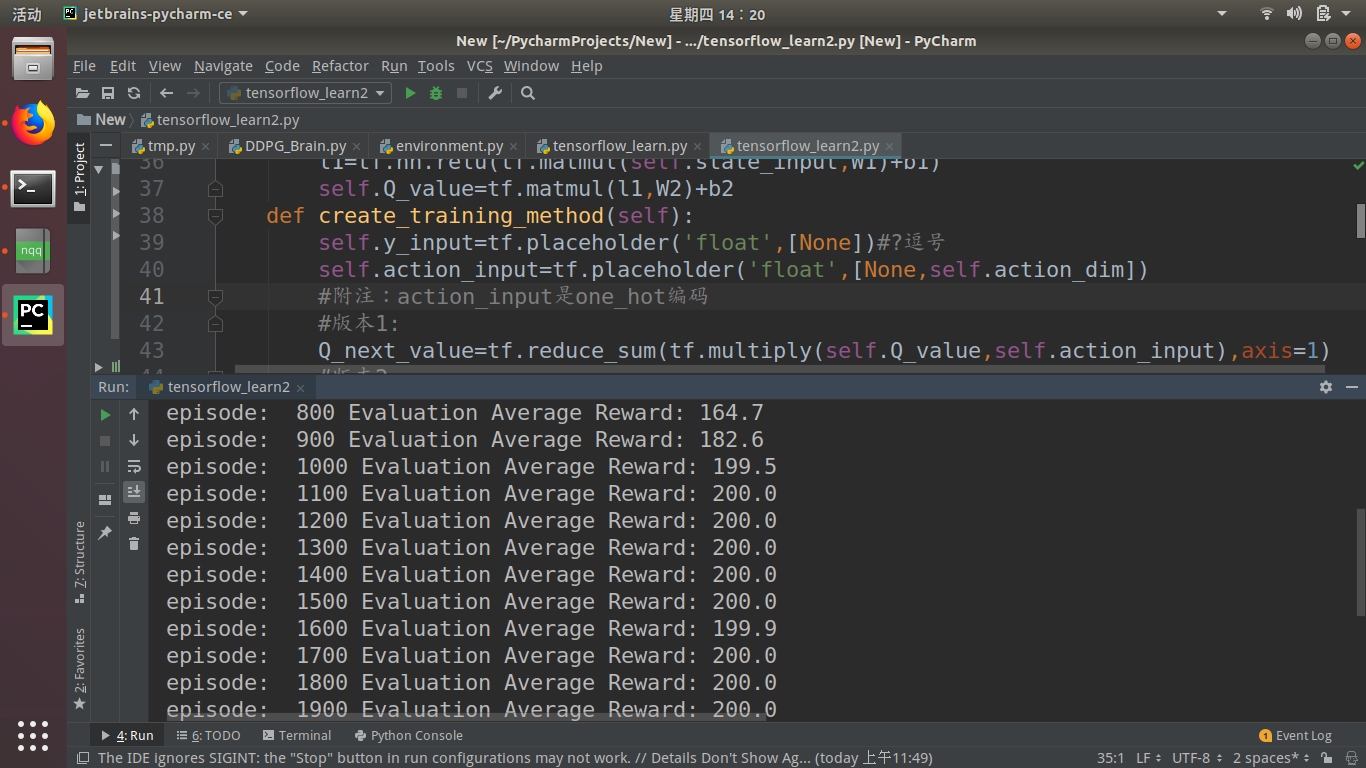
tensorflow 实现 DQN2013版 计算max(Q(snext))代码问题

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 你知我知皆知 2024-08-07 19:11关注
你知我知皆知 2024-08-07 19:11关注以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
在TensorFlow中,为了计算一个动作的最大Q值,可以使用以下方法:
# Q_eval 表示当前网络的输出 Q_eval = tf.reduce_max(self.Q_value, axis=1) # 使用最大Q值作为目标 target_Q = y_j + gamma * max(Q_next_values)其中
gamma为折扣因子,表示对未来的奖励进行折扣。在这个例子中,您已经成功地实现了版本一的代码。现在,请尝试将代码中的
one_hot_action更改为tf.argmax(Q_eval, axis=1)以获得动作的最大Q值,并再次训练模型。这应该会提供更好的结果。解决 无用评论 打赏举报 分享
- 2025-02-18 03:12WHCIS的博客 强化学习的核心是智能体(Agent)通过与环境的交互学习最优策略。其数学基础是马尔可夫决策过程(MDP),由五元组。:用深度神经网络代替Q表,解决高维状态空间问题。
- 2022-11-18 10:11鹏阿鹏的博客 CartPole问题:黑色小车上面支撑的一个连接杆,连杆会自由摆动,我们需要控制黑色小车,通过控制小车左右移动,保持连杆的平衡。该问题的动作空间是离散的且有限的,只有两种执行动作(0或1),但是该问题的状态空间...
- 2024-06-11 11:09沐风—云端行者的博客 通过上述代码,我们不仅理解了双DQN与优先级经验回放在理论上的优势,还实践了如何在TensorFlow框架下实现这一高级强化学习系统。结合两者,不仅提升了学习效率,还增强了模型的稳定性,这对于解决复杂、高维度的...
- 2025-12-31 15:19爱分析的博客 通过TensorFlow 2.9从零搭建深度Q网络,结合经验回放与目标网络训练智能体解决CartPole任务,详解模型构建、训练循环与稳定性技巧,并利用Docker镜像实现环境标准化,提升开发效率与实验可复现性。
- 2025-05-06 17:02光子AI的博客 本文旨在为读者提供从理论到实践的强化学习完整指南,特别关注如何使用TensorFlow框架实现两种最具代表性的强化学习算法:DQN和PPO。强化学习的基本原理和关键概念DQN算法的理论基础和实现细节PPO算法的数学原理和...
- 2020-08-10 14:57jsfantasy的博客 这篇文章我们就用代码来实现 DQN 算法 一、环境介绍 1、Gym 介绍 本算法以及以后文章要介绍的算法都会使用 由 OpenAIOpenAIOpenAI 推出的GymGymGym仿真环境, GymGymGym 是一个研究和开发强化学习相关算法的仿真平台...
- 2024-06-11 11:05沐风—云端行者的博客 通过上述代码示例,我们不仅理解了DQN算法的精髓,还亲自构建了一个简单的DQN模型解决CartPole平衡问题。DQN算法的成功在于其创新地结合了深度学习的表达力与Q学习的决策框架,为强化学习领域的突破性进展铺平了道路...
- 2020-08-26 15:07samurasun的博客 我们在“基础算法篇(四)值函数逼近方法解决强化学习问题”中介绍了经典的DQN算法,今天,我们就来点实际的,正式实现一下相关算法。 Tensorflow实现经典DQN算法一、基础游戏背景介绍二、建立文件与撰写主函数三、...
- 2025-12-27 12:38郑丢丢的博客 深入讲解如何使用TensorFlow实现深度Q网络(DQN)智能体,涵盖经验回放、目标网络、探索策略等核心机制,并结合工业级部署需求,展示从模型设计到生产落地的完整路径,突出TensorFlow在强化学习工程化中的优势。
- 2024-01-18 18:44全栈O-Jay的博客 使用深度Q网络(Deep Q-Network, DQN)来训练一个在openai-gym的LunarLander-v2环境中的强化学习agent,让小火箭成功着陆。全代码!
- 2024-06-06 00:37光子AI的博客 深度强化学习(Deep Reinforcement Learning,DRL)是近年来人工智能领域的热门研究方向之一。其中,深度Q网络(Deep Q-Network,DQN)是一种经典的DRL算法,被广泛应用于游戏、机器人控制等领域。而在实现DQN算法时...
- 2021-12-13 11:07剑未佩妥已入江湖的博客 使用tensorflow简洁快速的搭建DQN神经网络,只有建立网络、使用网络和训练网络三个代码,结构清楚
- 2025-07-18 13:46拉米医生的博客 在第一章中,我们将探索DQN算法的起源、其在深度强化学习领域的贡献以及它在多个领域中的应用案例。深度强化学习结合了深度学习与强化学习的优势,使其能在高维输入空间中自动学习特征表示和策略。我们将从强化学习...
- 没有解决我的问题, 去提问
