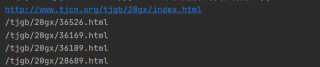
我成功爬取网站url后,得到的结果不是一个字符串,url的每个字符都单独变成一个字符串了,我用for i in herf: 得到的结果如下
/
t
j
g
b
/
2
0
g
x
/
1
9
7
8
0
.
h
t
m
l
以下是我写的程序
import re
import requests
from bs4 import BeautifulSoup
for page in range(0,10):
url = f"http://www.tjcn.org/tjgb/20gx/index_{page}.html"
if page == 0:
url = "http://www.tjcn.org/tjgb/20gx/index.html"
print(url)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"}
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
html = response.text
soup = BeautifulSoup(html, "lxml")
content_all = soup.find_all("a")
for item in content_all: # soup匹配到的有多个数据,用for循环取出
result = {
'title': item.get_text(), # 标签在<a>标签中,提取标签的正文用get_text()方法
'link': item.get('href'), # 链接在<a>标签的href中,提取标签中的href属性用get()方法,括号指定属性数据
}
result.get("title")
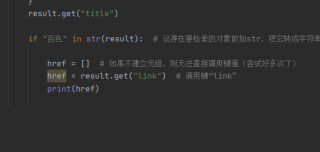
if "百色" in str(result): #记得在要检索的对象前加str,把它转成字符串穿,要不然无法搜索
href = [] #如果不建立元组,则无法直接调用键值(尝试好多次了)
href = result.get("link") #调用键“link”的值
for i in href:
print(i)