关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
terrybekhcam
2021-07-26 15:56
采纳率: 63.6%
浏览 2740
首页
Python
已结题
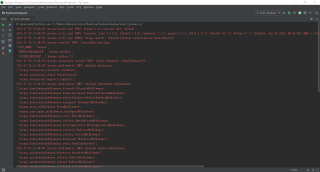
SCRAPY运行报错, [scrapy.core.engine] INFO: Spider closed (finished)!
python
Process finished with exit code 0
请问这个是运行成功,但被服务器拒绝了的意思吗?有什么办法处理?
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
2
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
python收藏家
2021-07-26 16:04
关注
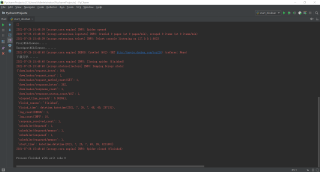
这个就是正常爬完了的日志信息吧,没啥问题啊
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(1条)
向“C知道”追问
报告相同问题?
提交
关注问题
Python
Scrapy
302 重定向导致
Clo
sing
spi
der
(f
ini
shed
),想要继续
运行
(已解决)
2021-08-06 11:13
孜然不辣的博客
2021-08-06 11:08:25 [
scrapy
.downloa
der
middlewares.redirect] DEBUG: Redirecting (302) to <GET https://tv.sohu.com/upload/static/special/anti-reptile/index.html> from <GET ...
Spi
der
clo
sed
(f
ini
shed
) 没完成
2020-12-29 01:46
AI算法网奇的博客
我猜测是
scrapy
的robot协议没关闭吧? settings.py中 1 2 #robots协议,True的话是遵守协议,所以要False关掉 ROBOTSTXT_OBEY=False
python
修改
scrapy
结束时显示开始时间和结束时间的时区
2022-02-13 21:55
星宇笔记的博客
scrapy
在每次
运行
结束后都会显示一堆统计数据信息,其中是有统计时间数据的,那个时间是 UTC 时间(0时区),不是我们平时习惯的系统本地时间,而且里面的爬虫总
运行
时间是以秒计算的,不符合我们的日常习惯,于是...
Python
实战演练之
scrapy
初体验
2020-03-03 17:13
fswy的博客
最近一直在做网络爬虫的练习,现在对整个爬取过程做个总结。 配置: 电脑:MacBook Pro 系统:macOS Catalina 10.15.3
Python
版本:3.8 ...
scrapy
安装我前面有在macOS成功在
python
3环境下安装
Scrapy
中提到,...
Python
-
Scrapy
框架入门及基本使用
2021-06-09 15:35
独角兽小马的博客
Scrapy
框架
Scrapy
基础知识1、简介2、五大组件
scrapy
框架创建1、创建
scrapy
项目2、简单入门
Scrapy
基础知识 1、简介 官网简介:
Scrapy
是一个用于抓取网站和提取结构化数据的应用程序框架,可用于各种有用的应用程序...
Python
爬虫——
Scrapy
-1
2024-03-07 09:46
WenJGo的博客
scrapy
入门,以及案例
关于
scrapy
mongodb pymongo.errors.AutoReconnect: connection
clo
sed
2021-10-15 16:59
大道至简_lyon的博客
File "C:\Users\li.pinliang\anaconda3\lib\site-packages\
scrapy
\utils\defer.py", line 161, in maybeDeferred_coro result = f(*args, **kw) File "C:\Users\li.pinliang\anaconda3\lib\site-packages\...
爬虫
Scrapy
框架项目
运行
时
报错
!求解决!
2018-03-26 15:05
kyrie_love的博客
E:\JetBrains\PyCharm\my
Spi
der
&...
scrapy
crawl itcast -o itcast.json2018-03-26 14:50:23 [
scrapy
.utils.log]
INFO
:
Scrapy
1.5.0 started (bot: my
Spi
der
)2018-03-26 14:50:23 [
scrapy
.utils.log]
INFO
: Version...
scrapy
学习笔记
2018-03-31 16:59
唐僧不爱八戒的博客
scrapy
是
python
最有名的爬虫框架之一,可以很方便的进行web抓取,并且提供了很强的定制型,这里记录简单学习的过程和在实际应用中会遇到的一些常见问题
Scrapy
运行
流程大概如下: 引擎从调度器中取出一个链接(URL)...
python
爬虫
scrapy
框架无法生成csv文件是怎么回事_[
python
爬虫] xpath没错,但运用
scrapy
框架无法爬到数据...
2020-11-21 03:28
weixin_39947908的博客
初学
scrapy
,我用
python
爬虫时使用
scrapy
框架爬取‘简书’的一些内容
运行
爬虫后,爬虫就关闭了,但什么内容都没爬取到网上类似的问答基本都说是xpath错了,导致无法抓取到数据但我用其他方法,相同的xpath能爬取到...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已结题
(查看结题原因)
8月6日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
8月1日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
7月26日

 分享
分享
 已结题
(查看结题原因) 8月6日
已结题
(查看结题原因) 8月6日

