
python3.7安装的 tensorflow缺少tensorflow.app.flags怎么解决?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

3条回答 默认 最新
 weixin_45103398 2020-09-24 17:25关注
weixin_45103398 2020-09-24 17:25关注我弄好了,现在不用.app这个了 直接tf.flags就OK
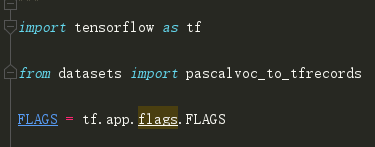
FLAGS = tf.flags.FLAGS
tf.flags.DEFINE_integer("is_train", 1, "指定程序是预测还是训练")评论 打赏解决 2无用 1举报 分享
- 2020-12-10 11:57weixin_39624700的博客 python打包工具都有哪些?主要有:py2exe、pyinstaller、cx_Freeze、nuitka等工具名称windowslinux是否支持单文件模式bbfreezeyesyesnopy2exeyesnoyespyinstalleryesyesyescx_Freezeyesyesnopy2...
- 2020-12-11 12:52weixin_39812039的博客 class Python < Formuladesc "Interpreted, interactive, object-oriented programming language"homepage ...
- 2021-01-29 00:56王者荣耀策划Donny的博客 1.说明:windows7 64位 + python3.7 + idea2018社区版2.首先是安装opencv,按照网上的说法都试了下,总结一下方法:使用pip下载,在cmd中 输入pythonpip install opencv-pythonpip install numpy安装numpy和opencv,...
- 2019-04-08 22:48一阙词的博客 tensorflow tf.app.flags 元素被重复定义及...FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_string('f','','kernel') result:(报错) The flag ‘f’ is defined twice. First from /home/huanghanchi/an...
- 2021-03-25 00:38趴着喝可乐的博客 显卡驱动安装2.protocolbuffers安装3.Python环境安装4.Tensorflow-gpu安装5.Object-detection安装安装 visual-cpp-build-tools安装 cocoapi安装 object-detection api安装 jupyter编写测试程序运行官方例子三、...
- 2020-07-30 02:02hamimelon2020的博客 (base) [ec2-user@ip-172-31-8-237 src]$ python -m openne --model gcn... File "/home/ec2-user/anaconda/lib/python3.7/runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "/home/ec2-user
- 2021-03-07 14:15清雨影的博客 object detection是...安装tensorflow官方的教程已经写得非常好了,这里就不多说,但是有一点必须注意的是,必须安装python3.6版本,不能安装最新的python3.7版本,不然会出现很多不兼容的问题难以处理。尽可能...
- 2024-03-27 11:26漂泊_人生的博客 PyInstaller是一个流行的工具,它可以将Python应用程序打包成独立的可执行文件,使其可以在没有安装Python解释器的系统上运行。如果您的系统中安装了多个Python版本,确保您使用的是系统认为的"默认"Python版本的pip...
- weixin_39647186的博客 1、前提条件:完成jupyter notebook安装2、生成密码python3.7>>from notebook.auth import passwd>>passwd() #输入密码后得到生成的密文,复制密文3、生成配置文件jupyter notebook --generate-config #...
- 2020-12-05 13:35weixin_39875503的博客 newlines=True,timeout=10,check=True) File "/usr/local/lib/python3.7/subprocess.py", line 487, in run output=stdout, stderr=stderr) subprocess.CalledProcessError: Command 'df -m &&netstat -ntslp|grep ...
- weixin_39678525的博客 我正试图帮助同事在我们的服务器上编译并运行Fortran模块。...环境:带Intel(R)Xeon(R)CPU E5-2697 v2的WinServer 2012R2编译器:tdm64-gcc-5.1.0-2.exe(在安装时检查Fortran支持)水蟒版本:4.5.11条Python版本:pyt...
- 2019-09-30 23:24Ljq730828的博客 ens33: flags=4163,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.81.129 netmask 255.255.255.0 broadcast 192.168.81.255 inet6 fe80::f08c:a9:42b2:6ec4 prefixlen 64 scopeid 0x20 ether 00:0c:29:11:...
- 2021-09-22 10:15Dave 扫地工的博客 5 分钟将 TensorFlow 1 代码转换到 TensorFlow 2 ...TensorFLow v1 原本是为了运行效率让用户直接使用 Python 操作计算图。 但是渐渐的用户发现: 调试困难 开发低效 各种 API 不统一 以及来自外部的 Keras 都让
- 2020-12-18 09:36weixin_39949607的博客 /usr/bin/env python#coding=gb2312import osimport sysimport win32apiimport win32conimport win32gui_structimport screenshottry:import winxpgui as win32guiexcept ImportError:import win32guiclass SysTra.....
- 2019-09-21 01:01weixin_30748995的博客 1、用TensorFlow训练一个物体检测器(手把手教学版) - 陈茂林的技术博客 - CSDN博客.html(https://blog.csdn.net/chenmaolin88/article/details/79357263) ZC:看的是这个教程,按照步骤一步一步来,做到 训练...
- 2025-11-12 23:19雨夜的星光的博客 本文系统分析了Python命令行参数解析工具的演进历程,通过实现一个问候脚本案例,对比了四种工具的特点:1) 最基础的sys.argv需要完全手动解析;2) 标准库argparse提供命令式API,功能强大但代码冗长;3) 第三方库...
- 2021-05-17 12:48瑞凤玉子烧的博客 基本参照我的这篇文章:《Windows下编译带CUDA 11.2的TensorFlow 2.4.1(Python3.9.1,cuDNN 8.1.0,兼容性3.5 - 8.6,附编译结果下载)》,有些地方有所改动。 环境准备 1. 内存要求 在8个并行任务下(默认并行...
- 2019-09-15 15:56分子美食家的博客 deepin10.15安装cuda10.1.168 cudnn7.6.1 tensorflow_gpu1.4.0 最近入坑deepin操作系统,基于debian9,和Ubuntu具有一样的操作习惯,由于是武汉团队开发的操作的系统,在易用性上更胜一筹,常见的qq,微信,搜狗...
- 没有解决我的问题, 去提问
