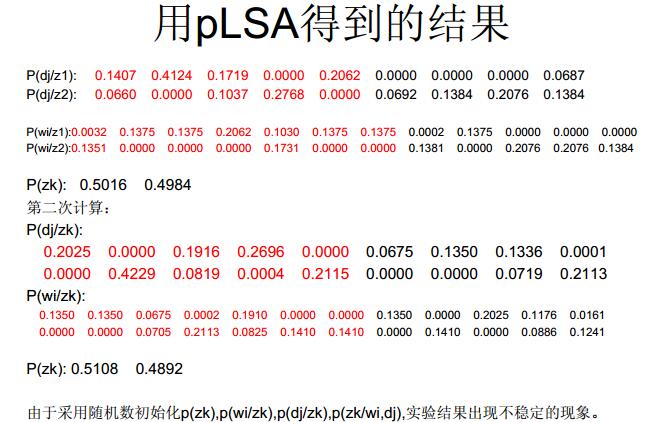
小白用pLSA得到了文档-主题概率矩阵、主题-词概率矩阵和主题概率矩阵(不确定有没有说错哈,反正就是三个矩阵嘛)
直接取最大概率对应的主题即该文档的主题?
有些论文还用了SVM分类,没搞明白。
走过路过的可爱大神们,求帮助~呜呜呜


小白用pLSA得到了文档-主题概率矩阵、主题-词概率矩阵和主题概率矩阵(不确定有没有说错哈,反正就是三个矩阵嘛)
直接取最大概率对应的主题即该文档的主题?
有些论文还用了SVM分类,没搞明白。
走过路过的可爱大神们,求帮助~呜呜呜
 分享
分享
以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
在给定的文本中,你提到使用了pLSA(概率线性判别分析)来获得文档-主题的概率矩阵和主题-词的概率矩阵。pLSA是一种无监督的学习方法,用于从稀疏数据中提取隐含模式。它通过计算每个文档与每个主题之间的相似度来确定文档属于哪个主题。
对于文档-主题的概率矩阵,你可以直接根据最大值选择最大概率对应的主题作为该文档的主题。例如:
max_prob_matrix = max(p_matrix)
selected_topic = topics(max_prob_matrix, k=num_topics)
这里max_prob_matrix是文档-主题的概率矩阵,topics函数用于找到具有最高概率的文档,k参数决定了要找出多少个主题。
至于如何使用SVM进行分类,这通常涉及到构建一个支持向量机模型,并使用训练好的模型对测试集进行预测。不过,你没有提供具体的训练和测试数据,因此我无法提供详细的指导。如果你有具体的数据集,请提供更多的信息以便我能更好地帮助你。
此外,需要注意的是,SVM是一种二分类算法,而你的问题似乎是关于多分类任务。如果确实是一个多分类问题,那么你需要先将文档-主题的概率矩阵转换为特征向量(比如使用TF-IDF或LDA),然后使用SVM进行多分类。
最后,这些步骤都是基于理论知识的解释,实际操作时可能需要结合实际情况来进行调整。希望这能帮到你!
分享
