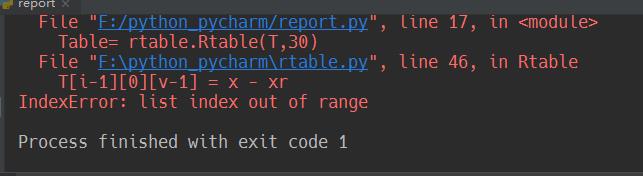
为什么会在代码倒数第二行出现IndexError: list index out of range错误,该如何解决?谢谢大佬
for x in range(columns):
for y in range(rows):
if (BW[y][x] == 255):
phi = ang[y][x]
i = round((phi + (math.pi / 2)) / d)
if (i == 0):
i = 1
v = F[i] + 1
if (v > s):
s = s + 1
T = [[[0 for j in range(entries)] for j in range(2)] for j in range(s)]
F[i-1] = F[i-1] + 1
T[i-1][1][v] = x - xr
T[i-1][2][v] = y - yr