

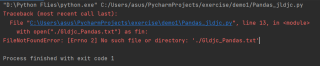
想利用Pandas借助Python爬虫爬取HTML网页表格保存到Excel文件,在运行过程中最后结果报错,如下图
程序如下
import requests
import requests.cookies
import json
import time
import pandas as pd
cookie_jar = requests.cookies.RequestsCookieJar
with open("./Gldjc_Pandas.txt") as fin:
cookiejson = json.loads(fin.read())
for cookie in cookiejson:
cookie_jar.set(
name=cookie["name"],
value=cookie["value"],
domain=cookie["domain"],
path=cookie["path"]
)
cookie_jar
htmls = []
url = "http://info.gldjc.com/info_price/a_l_p_cd_cl_m_k_pn1_so.html"
for idx in range(72):
time.sleep(1)
print("**爬数据: 第%d页" % idx)
r = requests.get(url.format(idx=idx), cookies=cookie_jar)
htmls.append(r.text)
htmls[0]
# 收集72个网页的表格
df_list = []
for html in htmls:
df = pd.read_html(html)
df_cont = df[1]
df_cont.columns = df[0].columns
df_list.append(df_cont)
# 合并多个表格
df_all = pd.contact(df_list)
df_all.head(4)
df_all.shape
# 4.Pandas将数据存储到Excel(pd.to_excel)
df_all[["序号", "材料名称", "规格型号", "单位", "除税价", "含税价", "历史价", "税率", "专业", "备注", "收藏"]].to_excel("./Gldjc_Pandas.txt/材料信息价列表.xlsx, index=False")








