
今天尝试写了一个爬取1688商品页的爬虫,发现1688的代码已经不同于几年前了,前台的页面html代码居然是通过js请求返回json数据中的值解析而来,整个动态加载的html被全部封装。在网页前台浏览的时候也能明显感觉到,整个商品页不是全部一次加载完成,随着鼠标的下滑进行动态加载,直至翻页出现。找了一下网上的爬取代码,不是代码太旧就是使用selenium,因此我尝试从解析js角度来看看能否爬到数据。
我搜索的关键词为:大理石餐盘,访问的url为:https://s.1688.com/selloffer/offer_search.htm?keywords=%B4%F3%C0%ED%CA%AF%B2%CD%C5%CC&n=y&netType=1%2C11&spm=a260k.635.3262836.d102
通过抓包可以发现实际上每个页面的动态加载通过如下的js文件加载: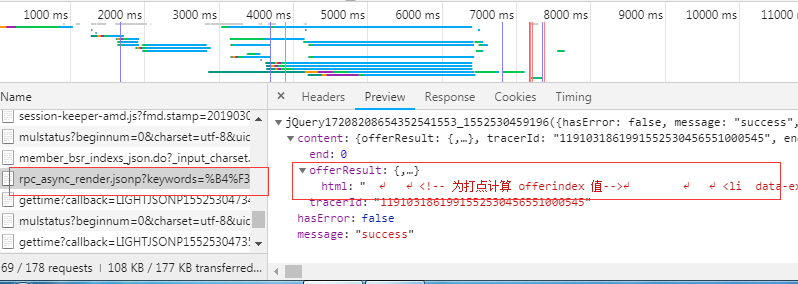
同时可以看到头部信息为:
因此我编写了代码来请求此url,想要获取其中的数据
通过分析url,我发现其实只有几个关键的参数在发生作用,我修改了url如下:
https://s.1688.com/selloffer/rpc_async_render.jsonp?keywords=%B4%F3%C0%ED%CA%AF%B2%CD%C5%CC&beginPage=2&startIndex=40&templateConfigName=marketOfferresult&async=true&enableAsync=true
将比较关键的参数罗列:keywords,beginpage ,startindex(本页中以0.20.40循环),templateconfigname,async,enableasync
从页面请求的结果如下
https://s.1688.com/selloffer/rpc_async_render.jsonp?keywords=%B4%F3%C0%ED%CA%AF%B2%CD%C5%CC&beginPage=2&startIndex=40&templateConfigName=marketOfferresult&async=true&enableAsync=true
依据上面的分析我编写了代码:
'''
得到单页商品信息
'''
try:
print('正在爬取第%d页' % page)
for startindex in range(0, 2):
proxy = get_proxy()
url = 'https://s.1688.com/selloffer/rpc_async_render.jsonp'
data = {
'keywords': KEYWORD, # 搜索关键词,
'beginpage': str(page), # 页数
'templateConfigName': TemplateConfigName,
'startIndex': str(startindex*20),
'async': 'true',
'enableAsync': 'true'
}
headers = {
'User_Agent': random.choice(USER_AGENT),
'Referer':'https://s.1688.com/selloffer/offer_search.htm?keywords=' + quote(
KEYWORD) + '&n=y&netType=1%2C11&spm=a260k.635.3262836.d102&offset=9&filterP4pIds=580281266813,551252714239,554311584303,554434844511,576452898982,567623615791,1264995609,584747673985',
'Cookie': COOKIE,
}
proxies = {"http": "http://{}".format(proxy)}
response = requests.get(url=url, headers=headers, params=data, proxies=proxies, timeout=5)
time.sleep(1)
if response.status_code == 200:
print(response.text)
data = response.json()
get_info(data=data)
except Exception as e:
print(e.args)
print('出现异常,重新爬取第%d页' % page)
return get_one_page(page)
其中请求头是参照抓包的请求头进行了伪装,user_agent使用了随机代理池中的代理。
ip应用了代理池中的代理进行切换, 测试代码发现虽然返回成功,但是内容为空:
测试代码的结果如下:
正在爬取第1页_
({
"hasError":false,
"message":"success",
"content":{
"offerResult":{
"html":""
},
"beaconP4Pid":"1552531611011186199615",
"tracerId":"1191031861991552531610953000954",
"end":0
}
})
很明显服务器判断出来我是机器人,我检查了一下cookies还有ip以及header都没有问题
使用同样的参数在浏览器页面请求也能访问正常的结果,因此我决定增加更多的参数,也许是因为服务器
端验证会检测某个参数是否存在来判断请求来自机器人还是真正的用户,我将代码修改如下:
def get_one_page(page):
'''
得到单页商品信息
'''
try:
print('正在爬取第%d页' % page)
for startindex in range(0, 2):
proxy = get_proxy()
url = 'https://s.1688.com/selloffer/rpc_async_render.jsonp'
data = {
'keywords': KEYWORD, # 搜索关键词,
'beginpage': str(page), # 页数
'templateConfigName': TemplateConfigName,
'startIndex': str(startindex*20),
'async': 'true',
'enableAsync': 'true',
'rpcflag': 'new',
'_pageName_': 'market',
'offset': str(9),
'pageSize': str(60),
'asyncCount': str(20),
'n': 'y',
'netType': '1%2C11',
'uniqfield': 'pic_tag_id',
'qrwRedirectEnabled': 'false',
'filterP4pIds': '550656542618%2C554434844511%2C574540124248%2C568185683625%2C567623615791%2C536778930216%2C577066747130%2C555894336804',
'leftP4PIds': '',
'pageOffset': str(3)
}
headers = {
'User_Agent': random.choice(USER_AGENT),
'Referer':'https://s.1688.com/selloffer/offer_search.htm?keywords=' + quote(
KEYWORD) + '&n=y&netType=1%2C11&spm=a260k.635.3262836.d102&offset=9&filterP4pIds=580281266813,551252714239,554311584303,554434844511,576452898982,567623615791,1264995609,584747673985',
'Cookie': COOKIE,
}
proxies = {"http": "http://{}".format(proxy)}
response = requests.get(url=url, headers=headers, params=data, proxies=proxies, timeout=5)
time.sleep(1)
if response.status_code == 200:
print(response.text)
data = response.json()
get_info(data=data)
except Exception as e:
print(e.args)
print('出现异常,重新爬取第%d页' % page)
return get_one_page(page)
测试的结果如下:
正在爬取第1页
({
"hasError":false,
"message":"success",
"content":{
"offerResult":{
"html":" \n \n <!-- 为打点计算 offerindex 值-->\n \n \n <!-- 用于异步请求 -->\n \n\n <div id=\"sm-maindata-script\">\n <script type=\"text\/javascript\">\n var coaseParam = {\n \'isCoaseOut\':true\n };\n <\/script>\n <script type=\"text\/javascript\">\n var rightP4P = {\n industryTagPath:\'\',\n leftP4PId:\'\',\n leftP4PLoginId:\'\',\n biaowangId:\'\'\n };\n var rightP4Poffer =[\n ];\n<\/script>\n <\/div>\n \n\n"
},
"beaconP4Pid":"1552532048109186199394",
"tracerId":"1191031861991552532048084000548",
"end":0
}
})
很遗憾结果并不理想,仍旧没有办法获得真正的数据。
我分析了还没有被我列进去的参数,因为无法寻找到其规律所以就没有加上去。
难道1688现在已经做到了,机器人无法爬的地步了吗,到底应该如何解决呢。有没有大神能够指点一下:
另外我同样的测试了一下1688的热销市场,同样的方式,没有问题可以爬取到js的内容,只不过数据是直接封装在json返回值中的,不是通过html代码二次封装。



