
我想實現這樣的圖,loss和acc兩條一起
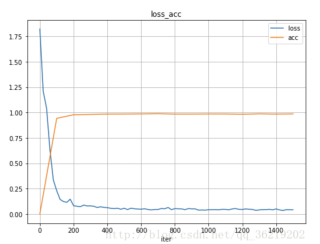
但我試了卻畫不出來,請問問題出在哪裡:(
我的程式碼:
import argparse
import os
from collections import OrderedDict
from glob import glob
import pandas as pd
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.optim as optim
import yaml
import numpy
from albumentations.augmentations import transforms
from albumentations.core.composition import Compose, OneOf
from sklearn.model_selection import train_test_split
from torch.optim import lr_scheduler
from tqdm import tqdm
import losses
from dataset import Dataset
from metrics import iou_score
from metrics import acc_score
from utils import AverageMeter, str2bool
import matplotlib.pyplot as plt
import time
tStart = time.time()#計時開始
ARCH_NAMES = archs.__all__
LOSS_NAMES = losses.__all__
LOSS_NAMES.append('BCEWithLogitsLoss')
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--name', default=None,
help='model name: (default: arch+timestamp)')
parser.add_argument('--epochs', default=10, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('-b', '--batch_size', default=10, type=int,
metavar='N', help='mini-batch size (default: 16)')
# model
parser.add_argument('--arch', '-a', metavar='ARCH', default='NestedUNet',
choices=ARCH_NAMES,
help='model architecture: ' +
' | '.join(ARCH_NAMES) +
' (default: NestedUNet)')
parser.add_argument('--deep_supervision', default=False, type=str2bool)
parser.add_argument('--input_channels', default=3, type=int,
help='input channels')
parser.add_argument('--num_classes', default=1, type=int,
help='number of classes')
parser.add_argument('--input_w', default=256, type=int,
help='image width')
parser.add_argument('--input_h', default=256, type=int,
help='image height')
# loss
parser.add_argument('--loss', default='BCEDiceLoss',
choices=LOSS_NAMES,
help='loss: ' +
' | '.join(LOSS_NAMES) +
' (default: BCEDiceLoss)')
# dataset
parser.add_argument('--dataset', default='dsb2018_96',
help='dataset name')
parser.add_argument('--img_ext', default='.jpg',
help='image file extension')
parser.add_argument('--mask_ext', default='.jpg',
help='mask file extension')
# optimizer
parser.add_argument('--optimizer', default='Adam',
choices=['Adam', 'SGD'],
help='loss: ' +
' | '.join(['Adam', 'SGD']) +
' (default: Adam)')
parser.add_argument('--lr', '--learning_rate', default=1e-3, type=float,
metavar='LR', help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float,
help='momentum')
parser.add_argument('--weight_decay', default=1e-4, type=float,
help='weight decay')
parser.add_argument('--nesterov', default=False, type=str2bool,
help='nesterov')
# scheduler
parser.add_argument('--scheduler', default='CosineAnnealingLR',
choices=['CosineAnnealingLR', 'ReduceLROnPlateau', 'MultiStepLR', 'ConstantLR'])
parser.add_argument('--min_lr', default=1e-5, type=float,
help='minimum learning rate')
parser.add_argument('--factor', default=0.1, type=float)
parser.add_argument('--patience', default=2, type=int)
parser.add_argument('--milestones', default='1,2', type=str)
parser.add_argument('--gamma', default=2/3, type=float)
parser.add_argument('--early_stopping', default=-1, type=int,
metavar='N', help='early stopping (default: -1)')
parser.add_argument('--num_workers', default=4, type=int)
config = parser.parse_args()
return config
def train(config, train_loader, model, criterion, optimizer):
avg_meters = {'loss': AverageMeter(),
'iou': AverageMeter(),
'acc': AverageMeter()}
model.train()
pbar = tqdm(total=len(train_loader))
for input, target, _ in train_loader:
input = input.cuda()
target = target.cuda()
# compute output
if config['deep_supervision']:
outputs = model(input)
loss = 0
for output in outputs:
loss += criterion(output, target)
loss /= len(outputs)
iou = iou_score(outputs[-1], target)
acc = acc_score(outputs[-1], target)
else:
output = model(input)
loss = criterion(output, target)
iou = iou_score(output, target)
acc = acc_score(output, target)
# compute gradient and do optimizing step
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_meters['loss'].update(loss.item(), input.size(0))
avg_meters['iou'].update(iou, input.size(0))
avg_meters['acc'].update(acc, input.size(0))
postfix = OrderedDict([
('loss', avg_meters['loss'].avg),
('iou', avg_meters['iou'].avg),
('acc', avg_meters['acc'].avg)
])
pbar.set_postfix(postfix)
pbar.update(1)
pbar.close()
return OrderedDict([('loss', avg_meters['loss'].avg),
('iou', avg_meters['iou'].avg),
('acc', avg_meters['acc'].avg)])
def validate(config, val_loader, model, criterion):
avg_meters = {'loss': AverageMeter(),
'iou': AverageMeter(),
'acc': AverageMeter()
}
# switch to evaluate mode
model.eval()
with torch.no_grad():
pbar = tqdm(total=len(val_loader))
for input, target, _ in val_loader:
input = input.cuda()
target = target.cuda()
# compute output
if config['deep_supervision']:
outputs = model(input)
loss = 0
for output in outputs:
loss += criterion(output, target)
loss /= len(outputs)
iou = iou_score(outputs[-1], target)
acc = acc_score(outputs[-1], target)
else:
output = model(input)
loss = criterion(output, target)
iou = iou_score(output, target)
acc = acc_score(output, target)
avg_meters['loss'].update(loss.item(), input.size(0))
avg_meters['iou'].update(iou, input.size(0))
avg_meters['acc'].update(iou, input.size(0))
postfix = OrderedDict([
('loss', avg_meters['loss'].avg),
('iou', avg_meters['iou'].avg),
('acc', avg_meters['acc'].avg)
])
pbar.set_postfix(postfix)
pbar.update(1)
pbar.close()
return OrderedDict([('loss', avg_meters['loss'].avg),
('iou', avg_meters['iou'].avg),
('acc', avg_meters['acc'].avg)])
def main():
config = vars(parse_args())
if config['name'] is None:
if config['deep_supervision']:
config['name'] = '%s_%s_wDS' % (config['dataset'], config['arch'])
else:
config['name'] = '%s_%s_woDS' % (config['dataset'], config['arch'])
os.makedirs('models/%s' % config['name'], exist_ok=True)
print('-' * 20)
for key in config:
print('%s: %s' % (key, config[key]))
print('-' * 20)
with open('models/%s/config.yml' % config['name'], 'w') as f:
yaml.dump(config, f)
# define loss function (criterion)
if config['loss'] == 'BCEWithLogitsLoss':
criterion = nn.BCEWithLogitsLoss().cuda()
else:
criterion = losses.__dict__[config['loss']]().cuda()
cudnn.benchmark = True
# create model
print("=> creating model %s" % config['arch'])
model = archs.__dict__[config['arch']](config['num_classes'],
config['input_channels'],
config['deep_supervision'])
model = model.cuda()
params = filter(lambda p: p.requires_grad, model.parameters())
if config['optimizer'] == 'Adam':
optimizer = optim.Adam(
params, lr=config['lr'], weight_decay=config['weight_decay'])
elif config['optimizer'] == 'SGD':
optimizer = optim.SGD(params, lr=config['lr'], momentum=config['momentum'],
nesterov=config['nesterov'], weight_decay=config['weight_decay'])
else:
raise NotImplementedError
if config['scheduler'] == 'CosineAnnealingLR':
scheduler = lr_scheduler.CosineAnnealingLR(
optimizer, T_max=config['epochs'], eta_min=config['min_lr'])
elif config['scheduler'] == 'ReduceLROnPlateau':
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, factor=config['factor'], patience=config['patience'],
verbose=1, min_lr=config['min_lr'])
elif config['scheduler'] == 'MultiStepLR':
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[int(e) for e in config['milestones'].split(',')], gamma=config['gamma'])
elif config['scheduler'] == 'ConstantLR':
scheduler = None
else:
raise NotImplementedError
# Data loading code
img_ids = glob(os.path.join('inputs', config['dataset'], 'images', '*' + config['img_ext']))
img_ids = [os.path.splitext(os.path.basename(p))[0] for p in img_ids]
print("Total:",len(img_ids))
train_img_ids, val_img_ids = train_test_split(img_ids, test_size=0.2, random_state=41)
print("Train:",len(train_img_ids))
print("Val:", len(val_img_ids))
train_transform = Compose([
transforms.RandomRotate90(),
transforms.Flip(),
OneOf([
transforms.HueSaturationValue(),
transforms.RandomBrightness(),
transforms.RandomContrast(),
], p=1),
transforms.Resize(config['input_h'], config['input_w']),
transforms.Normalize(),
])
val_transform = Compose([
transforms.Resize(config['input_h'], config['input_w']),
transforms.Normalize(),
])
train_dataset = Dataset(
img_ids=train_img_ids,
img_dir=os.path.join('inputs', config['dataset'], 'images'),
mask_dir=os.path.join('inputs', config['dataset'], 'masks'),
img_ext=config['img_ext'],
mask_ext=config['mask_ext'],
num_classes=config['num_classes'],
transform=train_transform)
val_dataset = Dataset(
img_ids=val_img_ids,
img_dir=os.path.join('inputs', config['dataset'], 'images'),
mask_dir=os.path.join('inputs', config['dataset'], 'masks'),
img_ext=config['img_ext'],
mask_ext=config['mask_ext'],
num_classes=config['num_classes'],
transform=val_transform)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=config['batch_size'],
shuffle=True,
num_workers=config['num_workers'],
drop_last=True)
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=config['batch_size'],
shuffle=False,
num_workers=config['num_workers'],
drop_last=False)
log = OrderedDict([
('epoch', []),
('lr', []),
('loss', []),
('iou', []),
('acc', []),
('val_loss', []),
('val_iou', []),
('val_acc', []),
])
best_iou = 0
trigger = 0
for epoch in range(config['epochs']):
print('Epoch [%d/%d]' % (epoch, config['epochs']))
# train for one epoch
train_log = train(config, train_loader, model, criterion, optimizer)
# evaluate on validation set
val_log = validate(config, val_loader, model, criterion)
if config['scheduler'] == 'CosineAnnealingLR':
scheduler.step()
elif config['scheduler'] == 'ReduceLROnPlateau':
scheduler.step(val_log['loss'])
print('loss %.4f - iou %.4f - - acc %.4f - val_loss %.4f - val_iou %.4f - val_acc %.4f'
% (train_log['loss'], train_log['iou'], train_log['acc'],val_log['loss'], val_log['iou'], val_log['acc']))
plt.plot(['epochs'], numpy.array(['acc']))
plt.xlabel('epoch')
plt.ylabel('score')
plt.legend(['acc', 'loss'])
plt.title('Train vs Valid Accuracy')
log['epoch'].append(epoch)
log['lr'].append(config['lr'])
log['loss'].append(train_log['loss'])
log['iou'].append(train_log['iou'])
log['acc'].append(train_log['acc'])
log['val_loss'].append(val_log['loss'])
log['val_iou'].append(val_log['iou'])
log['val_acc'].append(val_log['acc'])
pd.DataFrame(log).to_csv('models/%s/log.csv' %
config['name'], index=False)
trigger += 1
if val_log['iou'] > best_iou:
torch.save(model.state_dict(), 'models/%s/model.pth' %
config['name'])
best_iou = val_log['iou']
print("=> saved best model")
trigger = 0
# early stopping
if config['early_stopping'] >= 0 and trigger >= config['early_stopping']:
print("=> early stopping")
break
torch.cuda.empty_cache()
if __name__ == '__main__':
main()
def cttime(t):
fn = 'Process statement1500.txt' # 檔案名稱
Tn = 'Process time: '
tf = time.strftime("%H:%M:%S (H:M:S)", time.gmtime(t))
Tt = Tn+tf # 總花費時間
with open(fn, "w") as f:
f.write(Tt) # 輸出
tEnd = time.time()#計時結束
total = tEnd - tStart#列印結果,會自動做近位
print(total)
cttime(total)# 輸出總花費時間,名稱: Process statement.txt
plt.show()
請幫幫我,謝謝您!!







