




第1,2张图在ur1中输入网址后面输入200,date也改成200,返回的正是200对应页的数据;第3,4张图,换成i=200,把变量填进去,返回的是第一页数据,请问这是咋回事?
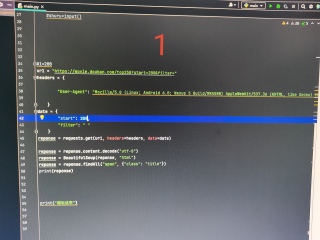
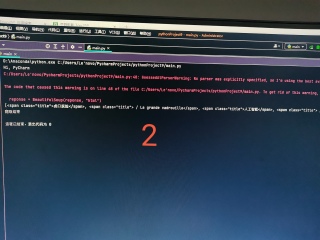
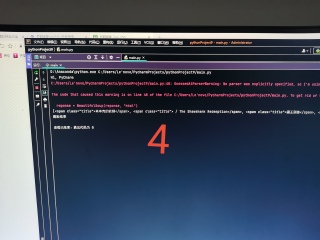
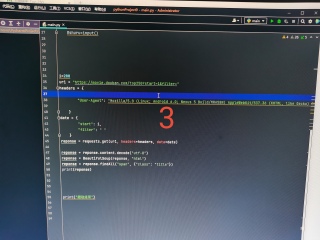

第1,2张图在ur1中输入网址后面输入200,date也改成200,返回的正是200对应页的数据;第3,4张图,换成i=200,把变量填进去,返回的是第一页数据,请问这是咋回事?
 分享
分享 系统已结题
11月1日
系统已结题
11月1日 已采纳回答
10月25日
创建了问题
10月25日
已采纳回答
10月25日
创建了问题
10月25日
























