我想知道这段爬虫代码有什么问题,为什么爬取不到我想要的信息呀
代码如下:
from lxml import etree
import requests
import csv
import time
fp = open('D:/Users/jack/Desktop/bilibili.csv', 'wt', newline='', encoding='utf-8-sig')
writer = csv.writer(fp)
writer.writerow(('up主', '视频名字', '视频链接', '时长', '观看人数', '上传时间'))
page = range(2, 34)
o = range(30, 510, 30)
urls = ['https://search.bilibili.com/video?keyword=python&from_source=webtop_search&spm_id_from=333.1007&search_source=3&page={}&o={}'.format(number, str(i)) for number, i in zip(page, o)]
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
for url in urls:
print(url)
time.sleep(2)
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
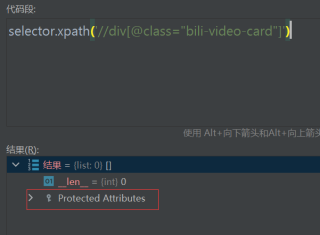
infos = selector.xpath('//div[@class="bili-video-card"]')
# infos = selector.xpath('//div[@id="i_cecream"]')
for info in infos:
up_name = info.xpath('div/div/p/a/span[1]')
print(up_name)
name = info.xpath('div/div/a/h3')
print(name)
url = info.xpath('div/div/a/@href')
print(url)
data = info.xpath('a/div/div[2]/div/span')
print(data)
see = info.xpath('a/div/div[2]/div/div/span[1]/span/text()')
print(see)
on_time = info.xpath('div/div/p/a/span[2]/text()')
print(on_time)
writer.writerow((up_name, name, url, data, see, on_time))
fp.close()
起初我的解决办法是去掉infos这个变量,但是不行,我还将infos变量改变了一下还是没用,但是我在网页试的时候是可以的
会的宝宝可以帮我看一下吗?万分感谢