在MyTransformer.ipynb中定义了一个Class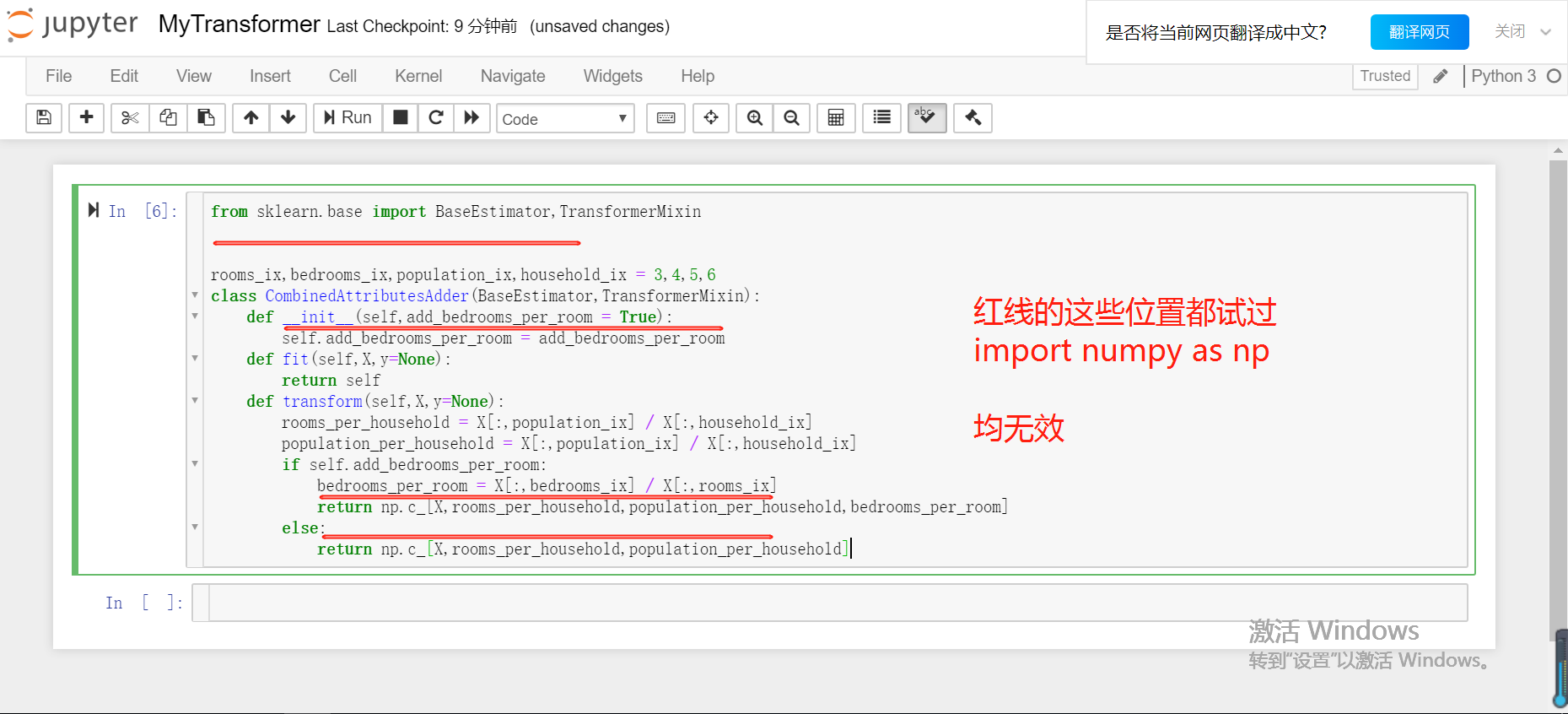
在另外一个ipynb中导入该文件,并调用该Class中定义的transform函数报错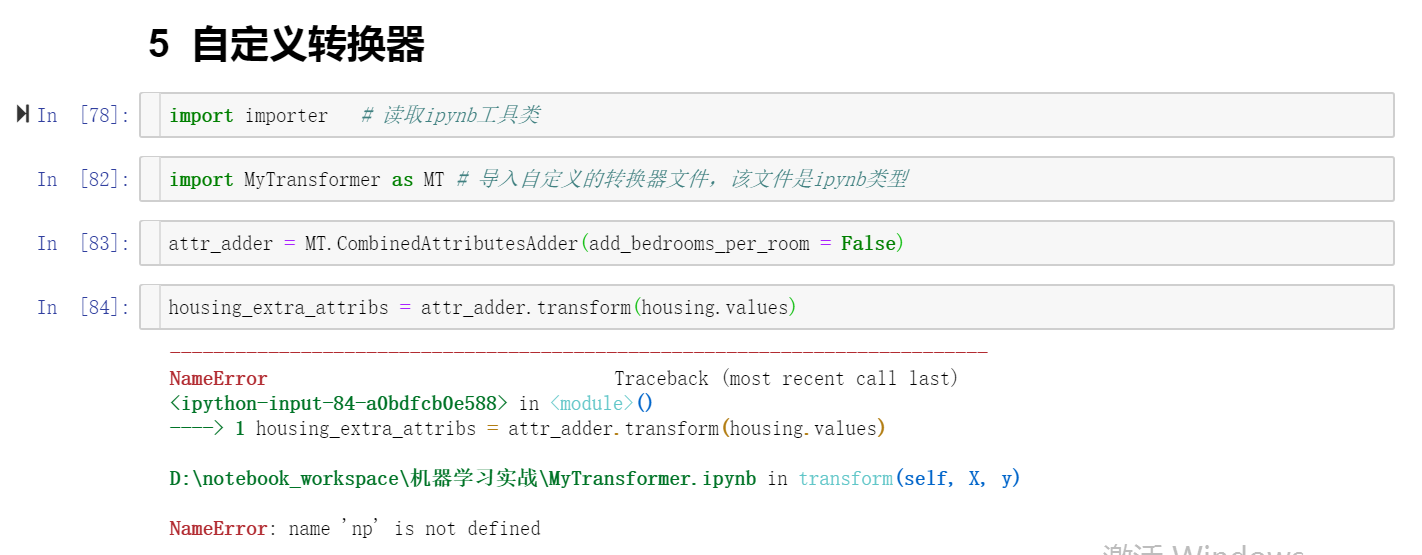
第二个图片的ipynb在上面导入了 numpy
求大神帮忙看看什么问题

在MyTransformer.ipynb中定义了一个Class
在另外一个ipynb中导入该文件,并调用该Class中定义的transform函数报错
第二个图片的ipynb在上面导入了 numpy
求大神帮忙看看什么问题
 分享
分享
就在第一幅图头导入numpy模块,没错的。
还是行不通的原因应该是:之前使用MyTransformer时,会在对应目录下生成一个对应的缓存文件,下次调用的时候会直接调用该缓存文件,
所以你即使你改过源码,还是没用的,删除掉机器学习实践目录下MyTransformer模块的缓存文件就ok了。
分享

