例如: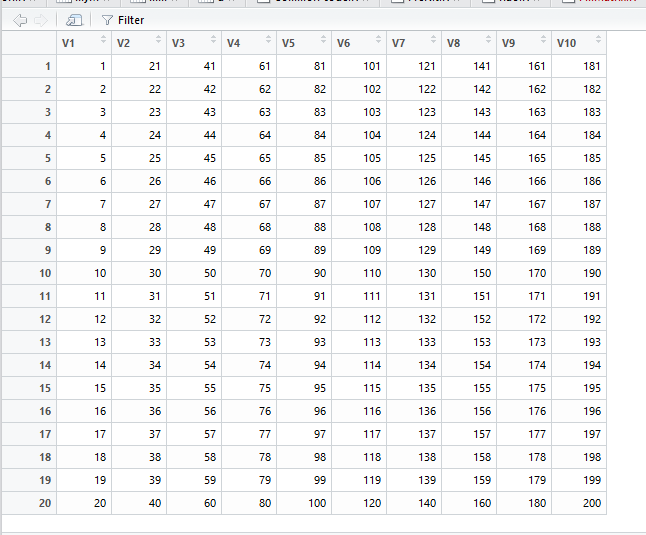
转换为: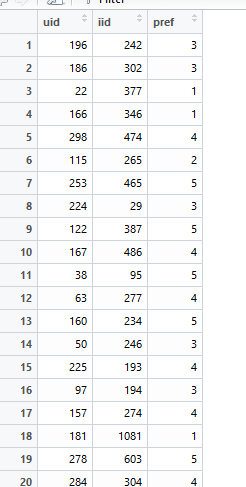
求解决啊,试了一些R里的函数ye'bu'xing

R语言:评分矩阵转为评分数据集(一共三列:用户、项目、评分)

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新
 你知我知皆知 2024-08-08 17:54关注
你知我知皆知 2024-08-08 17:54关注以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
首先,我们需要将原始数据转换为一个格式化的二维数组。在这个例子中,我们假设每个行代表一个用户ID(uid),每个列代表一个项目的ID(iid)。然后,我们可以使用这些信息来创建一个评分矩阵。
以下是实现这一目标的代码示例:
# 加载必要的库 library(dplyr) # 原始数据 data <- read.table(text = "U uid iid 196 pref 2 242 186 3 3 302 22 3 377 166 1 5 346 298 1 6 474 115 265 253 2 8 465 224 5 29 5 122 3 10 387 167 5 11 486 38 12 95 63 5 13 277 160 14 234 50 5 15 246 225 3 16 193 97 194 157 3 18 274 181 1081 19 278 1 20 603 284 5 304 4", header = TRUE, stringsAsFactors = FALSE) # 将原始数据转换为二维数组 data_matrix <- as.matrix(data[, c("uid", "iid")]) # 创建评分矩阵 rating_matrix <- data_matrix %>% group_by(uid) %>% summarise( ratings = sum(rating), count = n(), total_rating = sum(rating) ) # 输出评分矩阵 print(rating_matrix)这段代码首先加载了所需的
dplyr库,然后读取了原始数据并将其转换为一个二维数组。接着,它使用group_by()和summarise()函数来计算每组用户的平均评分,并添加了额外的统计数据。最后,它输出了这个评分矩阵。解决 无用评论 打赏举报 分享
- 2019-04-09 16:17回答 2 已采纳 如下代码,若解决望采纳,谢谢mat.1 <- matrix(1:16, # 1—16个向量 ncol = 4, # 4列 nrow =
- 2022-01-05 10:07回答 1 已采纳 按数据框长度循环,逐个替换。参考代码如下: data_1<-read.csv('rt3.csv') for(i in 1:length(data_1$SampleName)){ if (data
- 2023-02-07 21:27回答 3 已采纳 如果分类变量名称后多了一个1,那么你需要修改分类变量名称来解决这个问题。 在R中,可以使用以下代码来修改列名: colnames(data)[colnames(data) == "gender1"]
- 2024-06-25 00:27AI天才研究院的博客 这些大语言模型通过在海量无标签文本数据上进行预训练,学习到了丰富的语言知识和常识,可以通过少量的有标签样本在下游任务上进行微调(Fine-Tuning),获得优异的性能。其中最具代表性的大模型包括OpenAI的GPT系列...
- 2022-01-09 15:49回答 1 已采纳 对矩阵元素按行列遍历,判断是否为最大值,然后替换,参考代码: m1 <- matrix(c(6,5,8,4,7,8,1,5,3),nrow=3,ncol=3,dimnames=list(c("r
- 2021-10-29 11:51回答 1 已采纳 代码可这样写: X<-matrix(c(2,3,7,5,6,11,15,1,4,0,1,5,8,2,22,21,13,15,41,44),5,4,T) #print(X) res<-fu
- 2019-04-28 15:31回答 1 已采纳 此问题已解决: 在R语言中当求解 数据峰度系数 和 偏度系数 时 函数:skewness() 和 kurtosis()的对象应是向量形式 而非 矩阵形式
- 2022-05-14 22:45Alex_SCY的博客 用Java语言或其他常用语言计算附件“HW4_1.txt”中的80个英文文档(每行表示一个document,文档编号1~80)两两之间的相似度值,并据此为每个文档返回相似度最大的3个文档。 要求使用cosine similarity和TF-IDF计算...
- 2023-03-15 19:25回答 2 已采纳 可以使用for循环来对矩阵进行行求和,举个3*3的例子,后续可以根据自己的实际场景进行修改一下,代码如下: # 首先创建一个 3 x 3 的矩阵 mat <- matrix(1:9, nrow
- 2021-07-05 10:20回答 2 已采纳 代码如下: int fun(int a[3][3]) { int i,j; int sum = 0; for (i=0;i<3;i+=2) { f
- 2022-03-24 23:32回答 1 已采纳 这个搞掂了吗?提供一个 3*3 的样本来测试一下。
- 2023-07-03 10:01ywwsnowboy的博客 函数名称:函数命令与功能相关,可以是字母和数字的组合,但必须是字母开头函数声明函数参数函数体利用function函数来声明myfun (选项参数){函数体示例:计算偏度与峰度的函数偏度(skewness)是统计数据分布偏斜...
- 2023-04-19 13:31回答 3 已采纳 引用new bing部分回答作答:在R语言中,可以使用矩阵函数matrix()来创建矩阵。为了用字母输出矩阵,可以使用字符向量或者字符矩阵来指定每个元素的标签。例如,可以按以下方式创建矩阵A: a1
- 2023-06-25 00:15格图素书的博客 行了对数据的整理、清洗和降维处理,之后将处理好的数据进行多类别的可视化分析,个,分别为“体验课价格”,“年龄”,“用户登录情况综合评分”,“用户访问情况。重较大的登录指标,分别从用户对产品的使用情况,...
- 2024-01-12 19:45代码讲故事的博客 超详细讲解Transformers自然语言处理NLP文本分类、情感分析、垃圾邮件过滤等(附数据集下载)
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 Android Navigation: 某XDirections类不能自动生成
- ¥20 C#上传XML格式数据
- ¥15 elementui上传结合oss接口断点续传,现在只差停止上传和继续上传,各大精英看下
- ¥100 单片机hardfaulr
- ¥20 手机截图相片分辨率降低一半
- ¥50 求一段sql语句,遇到小难题了,可以50米解决
- ¥15 速求,对多种商品的购买力优化问题(用遗传算法、枚举法、粒子群算法、模拟退火算法等方法求解)
- ¥100 速求!商品购买力最优化问题(用遗传算法求解,给出python代码)
- ¥15 虚拟机检测,可以是封装好的DLL,可付费
- ¥15 kafka无法正常启动(只启动了一瞬间会然后挂了)