关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
知恩呐111
2021-11-05 23:39
采纳率: 50%
浏览 221
首页
大数据
已结题
搭建hadoop集群时,格式化失败
hadoop
大数据
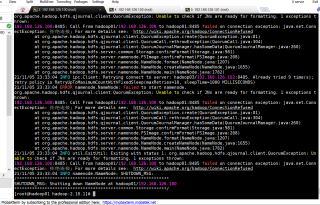
在第一次格式化成功后,主节点有namenode,但是从节点没有namenode,然后再一次进行格式化,就无法正常格式化。显示错误
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
2
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
yy64ll826
2021-11-08 21:53
关注
哈哈,我之前也遇到类似的问题,先启动dfs start-dfs.sh,在格式化,我前两天也上传一个Hadoop集群,可以看看
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
1
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(1条)
向“C知道”追问
报告相同问题?
提交
关注问题
Hadoop
大数据
集群
搭建
(超详细)
2023-05-21 18:30
小飞飞V5的博客
本文主要介绍了
Hadoop
集群
的
搭建
过程,图文详细,适合新手入门
基于centos的
大数据
hadoop
集群
搭建
说明文档
2022-10-30 11:21
【描述】:本教程专为初学者设计,详细阐述了如何手动
搭建
Hadoop
集群
,步骤详尽,易于理解。 【标签】:
Hadoop
集群
搭建
【正文】:
Hadoop
是一个开源的分布式计算框架,它允许在普通硬件上处理大量数据。基于...
Hadoop
大数据
集群
搭建
(超详细)_
hadoop
集群
搭建
2024-04-27 23:53
2401_84181070的博客
打开C:\Windows\System32\drivers\etc下的hosts文件,添加以下内容(注:如果没有notepad++这类软件,可以...传完之后要在
hadoop
02和
hadoop
03上分别执行 source /etc/profile 命令,来刷新配置文件。在
hadoop
01上执行。
【
大数据
】
搭建
Hadoop
集群
,超级详细
2022-07-12 10:40
小 源的博客
搭建
完全分布式运行模式(开发重点)1.1
Hadoop
部署1.2 配置
集群
1.3 配置历史服务器1.4 配置日志的聚集1.5 分发
Hadoop
1.6 群起
集群
1.7
Hadoop
群起脚本第2章 调优2.2.1 项目经验之HDFS存储多目录2.2.2
集群
数据均衡...
大数据
领域
Hadoop
集群
搭建
的详细步骤
2025-05-08 19:39
光子AI的博客
本文聚焦
Hadoop
3.3.6版本的
集群
搭建
,覆盖单Master多Slave的基础架构(生产环境可扩展为HA高可用架构),适用于企业级数据仓库、日志分析、离线计算等场景。核心概念:解析
Hadoop
架构与组件职责;环境准备:操作...
大数据
Hadoop
集群
搭建
2025-06-20 22:39
算法哥的博客
Hadoop
集群
环境
搭建
指南 本文详细介绍了
Hadoop
大数据
集群
环境的
搭建
过程,主要内容包括: VMware虚拟机准备:创建3台Linux虚拟机(node1/node2/node3),配置192.168.88.x网段,设置硬件参数(CPU/内存),并完成系统...
如何
搭建
hadoop
集群
2025-05-12 08:43
2301_82309799的博客
搭建
Hadoop
集群
需要准备多台服务器,并按照特定步骤配置。bash(所有节点):bash(所有节点):bash。
大数据
教程之
搭建
Hadoop
集群
.zip
2021-01-14 15:42
在
大数据
领域,
Hadoop
...总之,
搭建
Hadoop
集群
是一个涉及多步骤的过程,需要理解
Hadoop
的基本原理,并熟悉Linux环境下的系统管理和网络配置。通过这些文档和资源,你可以逐步学习并实践,建立起自己的
大数据
处理平台。
Hadoop
大数据
集群
搭建
详细教程
2022-08-21 14:29
dx1313113的博客
etc /vsftpd/ftpusers文件专门用于定义不允许访问FTP服务器的用户列表(注意:如果 userlist_enable=YES,userlist_deny=NO,此
时
如果在vsftpd.user_list和ftpusers中都有某个 用户
时
,那么这个用户是不能够访问FTP的,...
大数据
学习——
Hadoop
集群
完全分布式的
搭建
2024-07-11 01:45
Linux运维老纪的博客
Hadoop
集群
是一种分布式的计算平台,用来处理海量数据,它的两大核心组件分别是HDSF文件系统和分布式计算处理框架mapreduce。HDFS是分布式存储系统,其下的两个子项目分别是namenode和datanode;namenode管理着文件...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
11月23日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
11月15日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
11月5日


 分享
分享 分享
分享 系统已结题
11月23日
系统已结题
11月23日 已采纳回答
11月15日
创建了问题
11月5日
已采纳回答
11月15日
创建了问题
11月5日


