
import findspark
import pyspark
import math
findspark.init()
R = 6371.393
Pi = 3.14
def get_distance(taxi, district):
taxi_longitude = float(taxi[0])
taxi_latitude = float(taxi[1])
district_longitude = float(district[0])
district_latitude = float(district[1])
a = (math.sin(math.radians(taxi_latitude / 2 - district_latitude / 2))) ** 2
b = math.cos(taxi_latitude * Pi / 180) * math.cos(district_latitude * Pi / 180) * (
math.sin((taxi_longitude / 2 - district_longitude / 2) * Pi / 180)) ** 2
L = 2 * R * math.asin((a + b) ** 0.5)
return L
def get_label(distance, r):
if distance <= r:
return 1
else:
return 0
def print_rdd(x):
print(x)
if __name__ == '__main__':
conf = pyspark.SparkConf().setMaster("local[*]").setAppName("PySparkTest")
sc = pyspark.SparkContext(conf=conf)
district = sc.textFile(u'./data/district.txt')
taxi_gps = sc.textFile(u'./data/taxi_gps.txt')
district_data = district.map(lambda line: line.split(','))
taxi_data = taxi_gps.map(lambda line: line.split(',')[4:6])
merge_data = taxi_data.cartesian(district_data)
taxi_label = merge_data.map(lambda a: (a[1][0], get_label(get_distance(a[0], a[1][1:3]), float(a[1][3]))))
cnt = taxi_label.filter(lambda x: x[1] == 1).reduceByKey(lambda x, y: x + y)
print(cnt.collect())
# cnt.saveAsTextFile("./result")
初学pyspark,这是一个类似wordcount的问题,我是用pycharm做的,最后rdd的collect()输出结果会显示socket.timeout
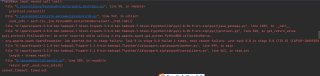
感觉可能是因为spark的慢处理机制,同时基于内存的操作,导致collect()失败,考虑到可能是数据太大了,导致collect()时内存不够,所以当我把两万条数据删到100条时,就会正常运行,所以可能就是数据量太大导致的,换了take()或者是foreach()以及尝试使用输出文件都不行,但是我舍友的mac同样的代码,同样spark和pyspark版本都是3.0.0是可以成功出结果的。总之,目前不知道怎么输出含有大量数据的rdd,会不会需要使用hdfs,或者说是别的问题,求解,谢谢!








