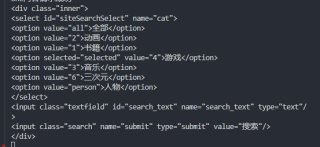
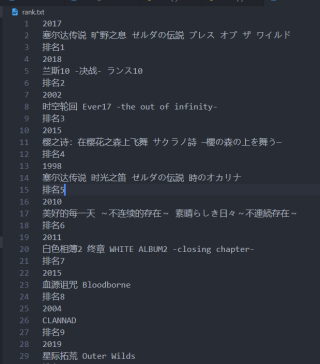
尝试用python爬虫,是在站内分享的代码基础上修改的(表示敬意
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
gamename = 'rank'
baseurl = "http://bgm.tv" # bangumi链接
url = baseurl + "/game/browser?sort=rank" # 要爬取的网页链接
col = ("年份", "名称", "排名",)
# 创建正则表达式对象
findChara = re.compile(r'<h3>(.*?)</h3>') # 作品信息
findCharaLink = re.compile(r'<p class="info tip"> (.*?)年') # 0.年份
findCharaJapanese = re.compile(r'<small class="gray">(.*?)</small>') # 1.名称
findCharaChinese = re.compile(r'</small>"(.*?)"</span>') # 2.排名
# 得到指定一个URL的网页内容
def askURL(url):
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
print("URL内容请求成功")
return html
# 给链接添加baseurl前缀,如果为空就返回空,否则返回baseurl + content
def reshapeLink(content):
if content == "":
return ""
else:
return baseurl + content
# 如果正则表达式返回为空列表,则返回"",否则返回第0个元素
def getContent(content):
if content == []:
return ""
else:
return content[0]
# 爬取网页
def getData(url):
datalist = [] # 用来存储爬取的网页信息
html = askURL(url) # 保存获取到的网页源码
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="inner"): # 查找符合要求的字符串
data = [] # 保存角色的对应信息
# 通过正则表达式查找
chara = re.findall(findChara, str(item))[0] # 作品信息
charalink = getContent(re.findall(findCharaLink, chara)) # 0.年份
data.append(reshapeLink(charalink))
charajapanese = getContent(re.findall(findCharaJapanese, chara)) # 1.排名
data.append(charajapanese)
charachinese = getContent(re.findall(findCharaChinese, chara)) # 2.名称
data.append(charachinese)
# 将信息添加到datalist里去
datalist.append(data)
#print(datalist)
return datalist
# 保存数据到txt
def saveTxt(datalist, savepath):
print("save txt.......")
txtfile = open(savepath, 'w', encoding='utf-8')
for i in range(0, len(datalist)):
txtfile.write(datalist[i][1]+"\n")
txtfile.write(datalist[i][2]+"\n")
txtfile.write("排名"+datalist[i][3]+"\n")
txtfile.close()
# main函数
if __name__ == "__main__":
# 1.爬取网页+解析数据
datalist = getData(url)
print("爬取完毕!")
# 3.当前目录创建TXT,保存数据
saveTxt(datalist, gamename+".txt")
print("输出完毕!")
在 for item in soup.find_all('div', class_="inner"): # 查找符合要求的字符串 一处将" "内改为inner后,启动调试显示 IndexError: list index out of range

对python不了解,恳请指点,比较急。感谢!