问题遇到的现象和发生背景
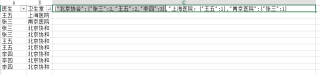
有三家医院,分别为北京,上海,南京,也有三名医生,分别叫张三、李四、王五,zhang
我想用padans统计每家医院的医生出现的次数,例如下面这家表,在北京医院里,名字叫张三的医生出现了2次,李四出现了3次,王五出现了两次,
则我希望得到一个字典,
这个字典是这样的: {"北京协会":{"张三":2,"王五":2,"李四":3}
注意:不同的医院可能有重名的医生,最后我希望在把所有医院放到一个字典里去,如:
{"北京协会":{"张三":2,"王五":2,"李四":3},"上海医院:{"王五":1},"南京医院":{"张三":1}
该怎么操作。