
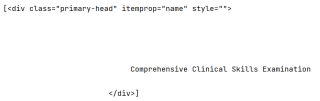
如图所示,这个div中间夹着的这段英文句子怎么提取出来?要剔除所有的换货和缩进。
谢谢各位

如图所示,这个div中间夹着的这段英文句子怎么提取出来?要剔除所有的换货和缩进。
谢谢各位
 分享
分享
原网页完全可以使用xlml之类的把字符串的源码转换为Element对象,然后用xpath之类的去解析,大概的代码应该是:
_ = etree.HTML(text)
data_list = _.xpath("//div[@class='primary-head']")
for data in data_list:
text = data.xpath("./text()")[0].replace('\r','').replace('\n','').strip() # 这边replace,strip是去掉换行空格之类的
单单用正则,代码为:
text = re.findall("style=\"\">([\s\S]*)<\/div>",sss)[0].replace('\r','').replace('\n','').strip()
print text
 系统已结题
12月15日
系统已结题
12月15日 已采纳回答
12月7日
修改了问题
12月7日
创建了问题
12月7日
已采纳回答
12月7日
修改了问题
12月7日
创建了问题
12月7日


