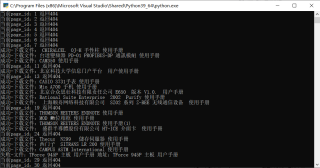
问题遇到的现象和发生背景
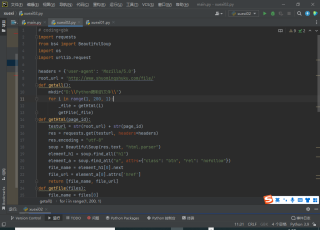
问题相关代码,请勿粘贴截图
# coding=gbk
import requests
from bs4 import BeautifulSoup
import os
import urllib.request
headers = {'user-agent': 'Mozilla/5.0'}
root_url = 'http://www.shuomingshuku.com/file/'
def getall():
mkdir("D:\\Python爬取的文件\\")
for i in range(1, 200, 1):
_file = getHtml(i)
getFile(_file)
def getHtml(page_id):
testurl = str(root_url) + str(page_id)
res = requests.get(testurl, headers=headers)
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
element_h1 = soup.find_all("h1")
element_a = soup.find_all("a", attrs={"class": "btn", "rel": "nofollow"})
file_name = element_h1[0].next
file_url = element_a[0].attrs['href']
return [file_name, file_url]
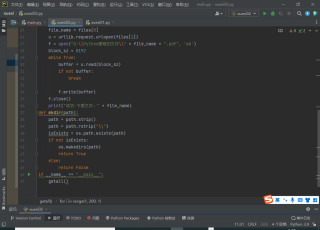
def getFile(files):
file_name = files[0]
u = urllib.request.urlopen(files[1])
f = open("D:\\Python爬取的文件\\" + file_name + ".pdf", 'wb')
block_sz = 8192
while True:
buffer = u.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print("成功-下载文件:" + file_name)
def mkdir(path):
path = path.strip()
path = path.rstrip("\\")
isExists = os.path.exists(path)
if not isExists:
os.makedirs(path)
return True
else:
return False
if __name__ == "__main__":
getall()
运行结果及报错内容
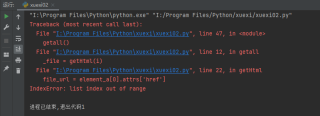
"I:\Program Files\Python\python.exe" "I:/Program Files/Python/xuexi/xuexi02.py"
Traceback (most recent call last):
File "I:\Program Files\Python\xuexi\xuexi02.py", line 47, in <module>
getall()
File "I:\Program Files\Python\xuexi\xuexi02.py", line 12, in getall
_file = getHtml(i)
File "I:\Program Files\Python\xuexi\xuexi02.py", line 22, in getHtml
file_url = element_a[0].attrs['href']
IndexError: list index out of range
我想要达到的结果