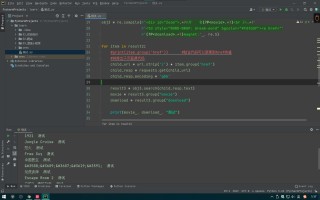
在pycharm中写的一个小爬虫,最后前面代码运行没有问题,都没有报错,但在最后输出结果时,只能输出电影名(即代码尾部的“movie”),对应的下载链接(尾部的“href”)就是无法输出到屏幕上。为了更直观的体现出来,我在后面增加了“测试”二字,这样更方便看出问题所在。
import requests
import re
url = 'https://www.dy2018.com/'
resp = requests.get(url)
resp.encoding = 'gbk'
#1.提取2021必看热片部分的HTML代码
obj1 = re.compile(r"2021必看热片.*?<ul>(?P<html>.*?)</ul>", re.S)
result1 = obj1.search(resp.text)
html = result1.group("html") # 拿到上面匹配到的href的值,并存储到html
#2.提取a标签中herf的值
obj2 = re.compile(r"<li><a href='(?P<href>.*?)' title=")
result2 = obj2.finditer(html) #html中的href太多,所以使用finditer
#3.提取下载链接
obj3 = re.compile(r'<div id="Zoom">.*?◎片 名(?P<movie>.*?)<br />.*?'
r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="'
r'(?P<download>.*?)magnet:' , re.S)
for item in result2:
#print(item.group('href')) #验证代码可以获取到href的值
#拼接出子页面源代码
child_url = url.strip('/') + item.group('href')
child_resp = requests.get(child_url)
child_resp.encoding = 'gbk'
result3 = obj3.search(child_resp.text)
print(child_resp.text)
'''
movie = result3.group("movie")
download = result3.group("download")
print(movie , download , "测试")
'''
print("======电影天堂提取完毕======")