python 怎么获取request 请求中 body的内容?
谢谢
就是红框中的内容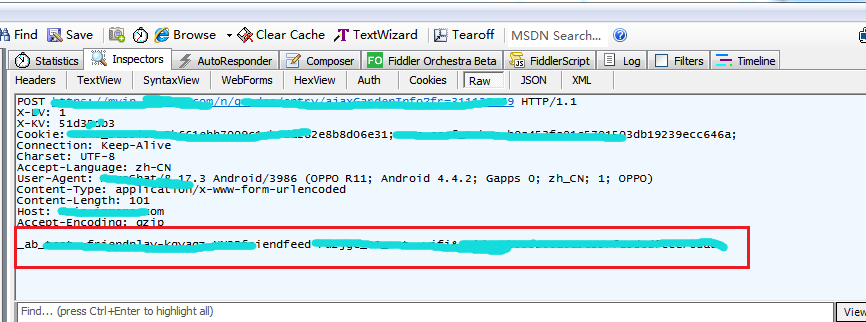
这是工具里模拟发送的,上图红框中的内容,是写在下面request body里的东西
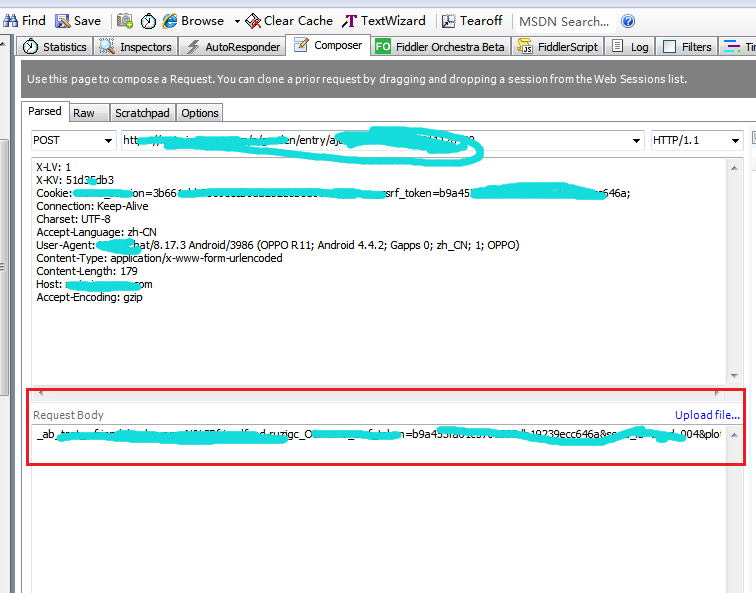
但是在python里模拟请求时,因为有ud的值是每次登陆时都变一次。
所以想怎么能在它本身发送request时把body里的内容保存下来。
这样就可以取出里面的ud值 使用
这样不知道我表述明白没。我也是在学习阶段。希望指教

python 怎么获取request 请求中 body的内容?
谢谢
就是红框中的内容
这是工具里模拟发送的,上图红框中的内容,是写在下面request body里的东西
但是在python里模拟请求时,因为有ud的值是每次登陆时都变一次。
所以想怎么能在它本身发送request时把body里的内容保存下来。
这样就可以取出里面的ud值 使用
这样不知道我表述明白没。我也是在学习阶段。希望指教
 分享
分享

