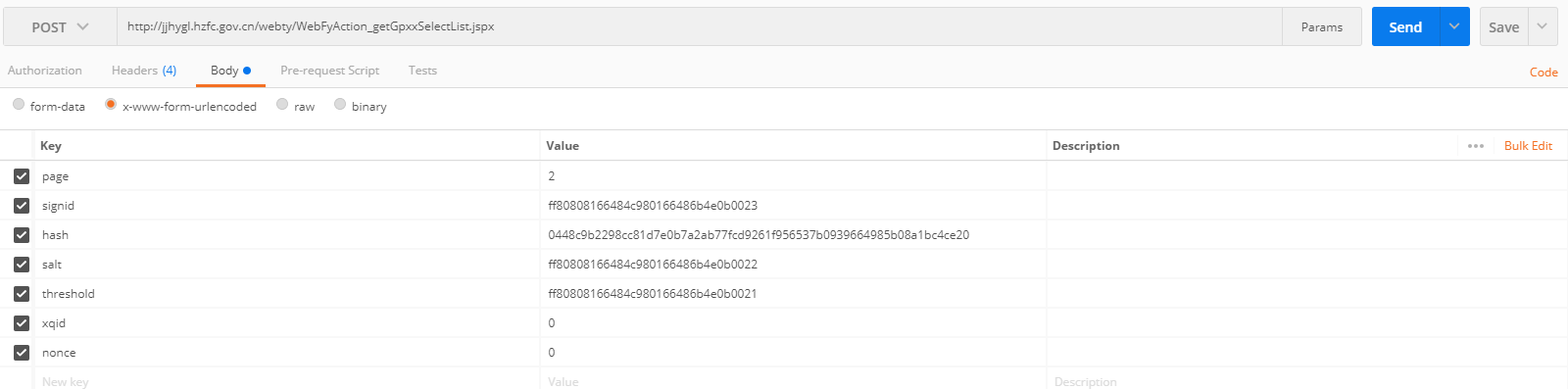
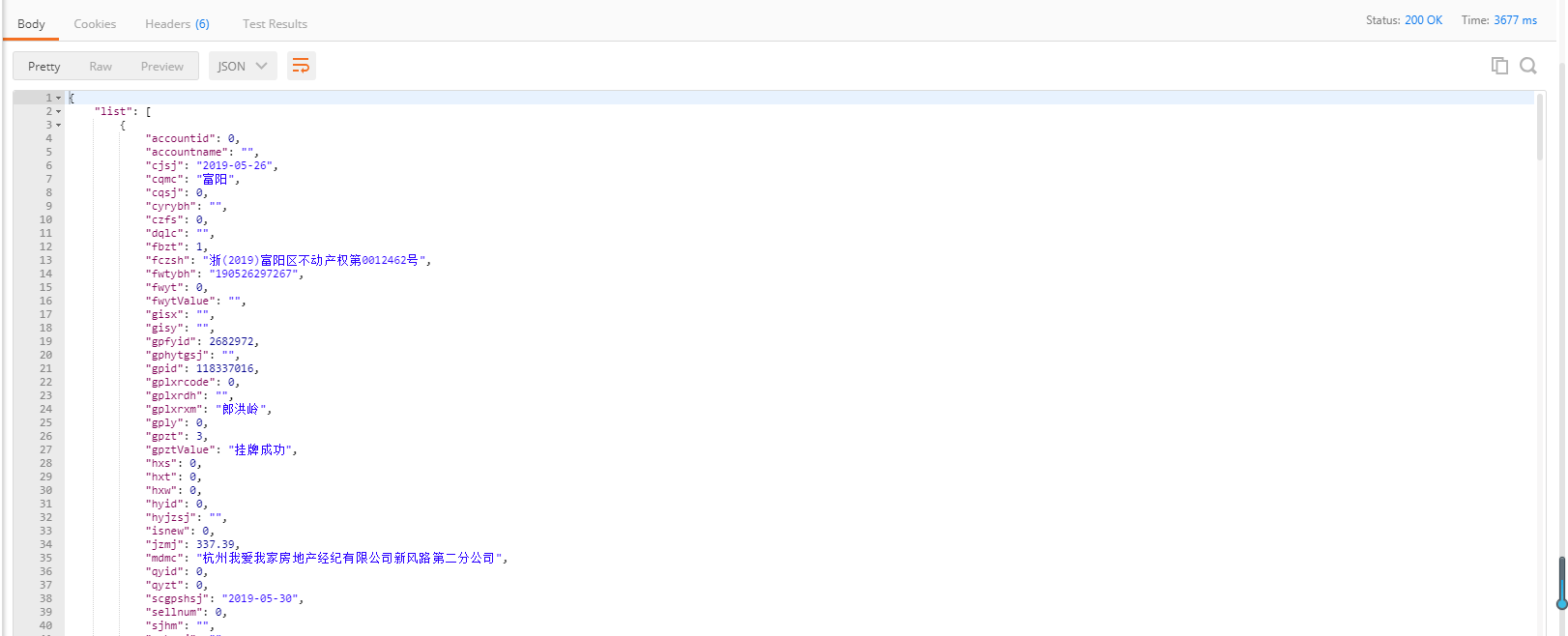
本人小白,尝试爬杭州市二手房挂牌信息,
网址:http://jjhygl.hzfc.gov.cn/webty/gpfy/gpfySelectlist.jsp,
代码如下
import requests
url = 'http://jjhygl.hzfc.gov.cn/webty/WebFyAction_getGpxxSelectList.jspx'
data = {'page': 1}
headers = {'Host': 'jjhygl.hzfc.gov.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0',
'Accept': 'text/html, */*; q=0.01',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip, deflate',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'Content-Length': '311',
'Connection': 'keep-alive',
'Referer': 'http://jjhygl.hzfc.gov.cn/webty/gpfy/gpfySelectlist.jsp',
'Cookie': 'ROUTEID=.lb6; JSESSIONID=2E78A1FE8DBC80F1CEEE20264BE96B1F.lb6; Hm_lvt_70e93e4ca4be30a221d21f76bb9dbdfa=1559115557; Hm_lpvt_70e93e4ca4be30a221d21f76bb9dbdfa=1559115557',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'}
r = requests.post(url, data =data, headers = headers)
r.content
r.text
返回结果是
b'{"list":[],"pageinfo":"\xe6\x9a\x82\xe6\x97\xa0\xe6\x95\xb0\xe6\x8d\xae"}'
'{"list":[],"pageinfo":"暂无数据"}'
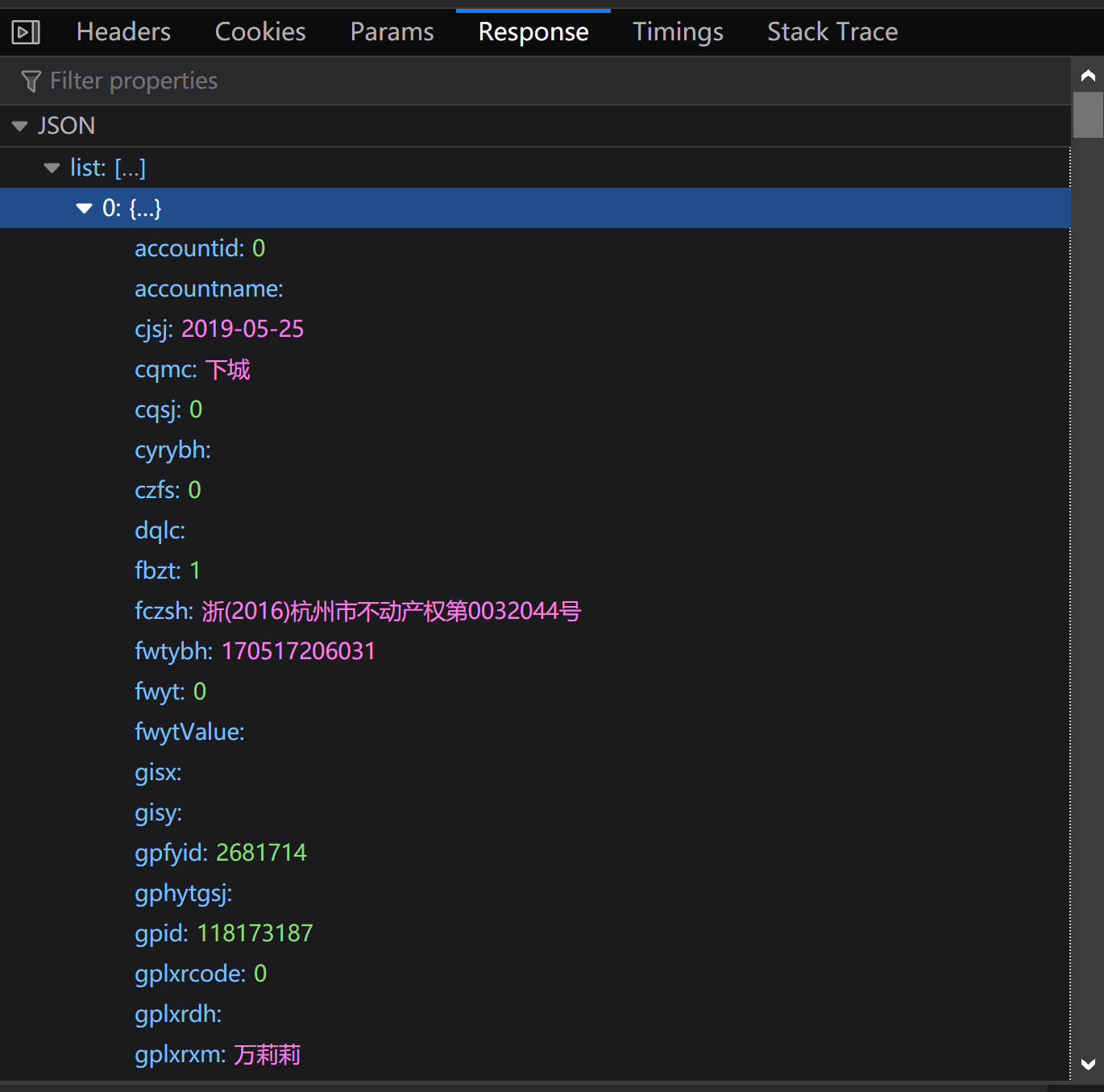
请问怎么才能得到图中的信息?