在获取了response响应中的内容后,需要将response的部分内容更新到cookie中。
但是获取response的内容实在自定义的parse函数中,而更新cookie是在Middleware中的process_request()中,那如何将Spider中的parse函数中的变量传递到Middleware中的process_request中呢?
下边是我的函数
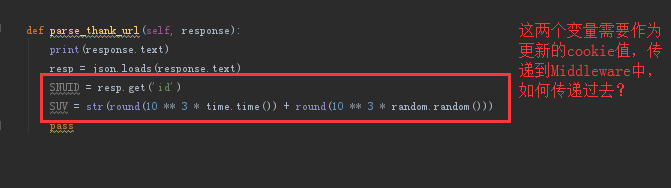
以上还请大神指点一下~~

在获取了response响应中的内容后,需要将response的部分内容更新到cookie中。
但是获取response的内容实在自定义的parse函数中,而更新cookie是在Middleware中的process_request()中,那如何将Spider中的parse函数中的变量传递到Middleware中的process_request中呢?
下边是我的函数
以上还请大神指点一下~~
 分享
分享




