
原有DataFrame为
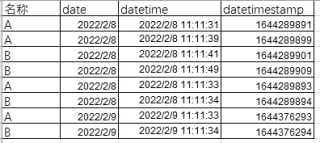
想使用groupby按照名称和date对DataFrame分组,并按照datetime由大到小排序。计算相同名称和date下的datetimestamp前后差值,前后名称或date不一致的用0代替差值.
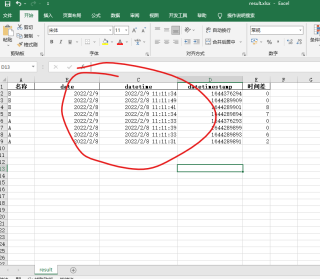
期望结果:
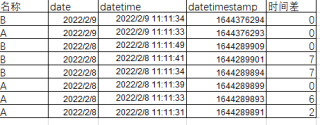

原有DataFrame为
想使用groupby按照名称和date对DataFrame分组,并按照datetime由大到小排序。计算相同名称和date下的datetimestamp前后差值,前后名称或date不一致的用0代替差值.
期望结果:
 分享
分享
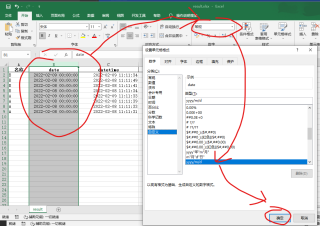
按照题主提供的图片,默认日期格式为excel日期格式YYYY/MM/DD等,要求位置单元格居右(而如果以str属性读取,内容会单元格居左)
我觉得你的文件可能还有后续的分析任务,所以建议结果文件中日期格式的处理在excel中操作比较好,如果没有后续工作了或者对格式的要求无所谓,或者在python中可以确定能对应好格式的,可以读取属性改为str或其他方式处理(比如pandas的to datetime,不过我也不会目前)
参考如下
import pandas as pd
excel_file = 'D:/PycharmProjects/pythonProject/datetime.xlsx' # 读取文件路径
result_file = 'D:/PycharmProjects/pythonProject/result.xlsx' # 保存文件路径
# 取代groupby,用sort_values即可,False为降序,先后顺序为['名称', 'date', 'datetime']
df = pd.read_excel(excel_file, sheet_name='datetime').sort_values(by=['名称', 'date', 'datetime'], ascending=[False, False, False])
df['时间差'] = 0 # 新建列‘时间差’,每行默认填充0
for row in range(1, df.shape[0]): # 从head下面的第二行内容开始遍历
if df.iloc[row, 0] == df.iloc[row-1, 0] and df.iloc[row, 1] == df.iloc[row-1, 1]: # 如果上一行名称及日期等于本行名称及日期
df.iloc[row, 4] = df.iloc[row-1, 3] - df.iloc[row, 3] # 时间差运算,赋值给对应的时间差列
df.to_excel(result_file, sheet_name='result', index=False) # 导出结果文件,sheet为‘result’
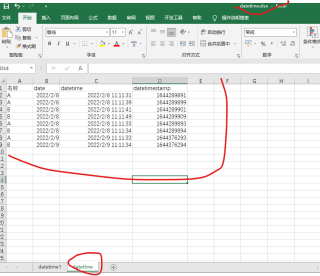
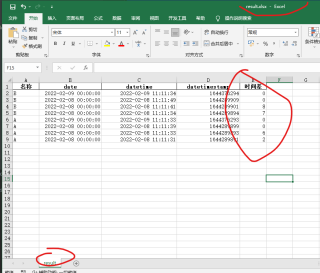
分享 系统已结题
2月22日
系统已结题
2月22日 已采纳回答
2月14日
创建了问题
2月14日
已采纳回答
2月14日
创建了问题
2月14日

