
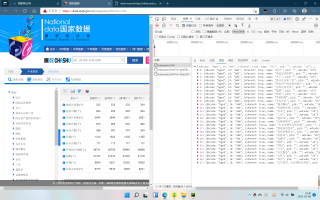
从网络预览可以看到,内容应该是一个列表,使用标头里的请求网址之后,返还的却是一个网页源码,这是为什么呢?

 分享
分享
requests.get得到的是源代码,ajax动态加载或者js动态生成的html代码获取不到,需要直接请求接口获取数据或者从源代码中找到js数据源进行解析。截图中右边块的数据接口为下面这个,直接requests.get请求接口获取数据就行
https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgyd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%5D&k1=1646787266750&h=1
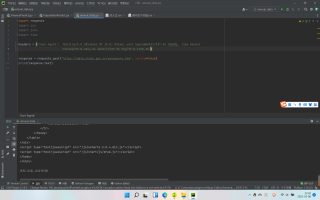
import requests
import json
import urllib3
url="https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgyd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%5D&k1=1646787266750&h=1"
requests.packages.urllib3.disable_warnings()
res=requests.get(url, verify=False)
res.encoding = 'utf8'
text=res.text
o=json.loads(text)
datanodes=o['returndata']['datanodes']#每个月份的数据节点
nodes=o['returndata']['wdnodes'][0]['nodes']#名称数组
for node in nodes:
code=node['code']
print(node['name'])
nodedata=[item for item in datanodes if item['code'].find('.'+code+'_')!=-1]
for data in nodedata:
print(data['code'].split('.')[-1],data['data']['data'])
print('\n\n\n')

分享 系统已结题
3月18日
系统已结题
3月18日 已采纳回答
3月10日
修改了问题
3月9日
修改了问题
3月9日
已采纳回答
3月10日
修改了问题
3月9日
修改了问题
3月9日


