
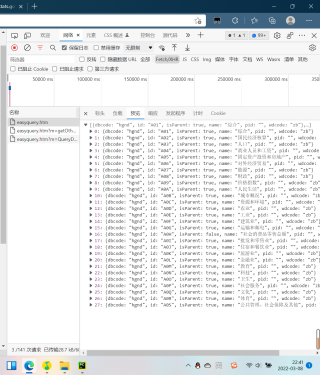
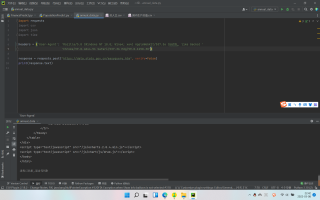
从网络预览可以看到,内容应该是一个列表,使用标头里的请求网址之后,返还的却是一个网页源码,这是为什么呢?

 分享
分享
 关注
关注看一下网页里内容是啥,无关内容就是被反爬了,因为这是ajax请求,你直接抓报请求,header头部可能会反爬,有时还要加cookie,referer,csrf等
分享 系统已结题
3月18日
系统已结题
3月18日 已采纳回答
3月10日
修改了问题
3月10日
创建了问题
3月9日
已采纳回答
3月10日
修改了问题
3月10日
创建了问题
3月9日


