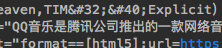
python中requests爬取text的空格为什么显示‘ ’?
像这一个应该是tim (explicit)的,怎么让它显示正确的格式, 或者怎么转换成这种形式?
收起
当前问题酬金
¥ 0 (可追加 ¥500)
支付方式
扫码支付
支付金额 15 元
提供问题酬金的用户不参与问题酬金结算和分配
支付即为同意 《付费问题酬金结算规则》
需要对实体进行解码操作https://blog.csdn.net/yiliumu/article/details/21229677
报告相同问题?

 分享
分享




