
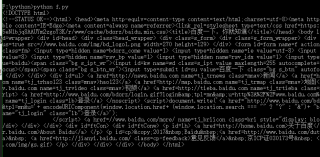
网络爬虫使用requests爬取百度出现了乱码l,搜狗确实正常的,请问怎么解决?
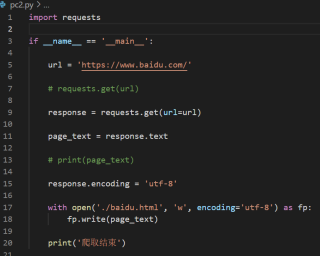

网络爬虫使用requests爬取百度出现了乱码l,搜狗确实正常的,请问怎么解决?
 分享
分享
response.encoding=utf-8放上来
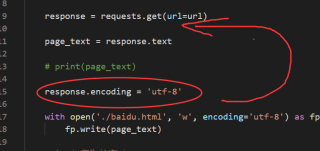
import requests
url='https://www.baidu.com/'
r=requests.get(url)
r.encoding='utf-8'
print(r.text)

分享 已结题
(查看结题原因) 3月29日
已采纳回答
3月24日
创建了问题
3月21日
已结题
(查看结题原因) 3月29日
已采纳回答
3月24日
创建了问题
3月21日




