import math
import os
from time import strftime, gmtime
import speech_recognition as sr
from googletrans import Translator
from moviepy.video.io.VideoFileClip import VideoFileClip
from pydub import AudioSegment
from pydub.silence import detect_nonsilent
# 修改google翻译地址
translator = Translator(service_urls=[
'translate.google.cn'
])
"""
转换srt格式时间,毫秒转时分秒
"""
def format_time(timestamp):
if timestamp is None:
return ''
second = math.modf(timestamp / 1000)
return strftime("%H:%M:%S", gmtime(second[1])) + ',' + str(int(round(second[0], 3) * 1000))
"""
调用google翻译
"""
def translate(text, dest='zh-cn'):
if text is None:
return text
if text == '':
return text
return translator.translate(text, dest=dest).text
"""
切割翻译结果,避免字幕显示过长
"""
def split_srt(text):
new_text = ''
# 长度大于20进行分割
while len(text) > 20:
new_text += text[:20] + '\n'
text = text[20:]
new_text += text[0:]
return new_text
"""
获取文件名
"""
def get_file_name(file):
path, name = os.path.split(file)
name, suffix = os.path.splitext(name)
return name
"""
生成字幕文件
"""
def generate_srt(srt_name, srt_content):
srt_file = srt_name + r'.srt'
with open(srt_file, "w", encoding='utf-8') as f:
f.write(srt_content)
"""
调用google在线翻译
"""
def recognize_google(recognizer, audioData, language):
result = recognizer.recognize_google(audioData, language=language, show_all=True)
if len(result) != 0:
return handle_result(language, result['alternative'][0]['transcript'])
"""
本地翻译
"""
def sphinx(recognizer, audioData, language):
result = recognizer.recognize_sphinx(audioData, language=language, show_all=True)
return handle_result(language, result.hyp().hypstr)
"""
处理翻译结果
"""
def handle_result(language, source_result):
if source_result is None:
return None
source_result = source_result.replace(" ", "")
if 'zh' not in language:
dest_result = translate(source_result)
return source_result, dest_result.replace(" ", "")
print("--"+source_result)
return source_result, ''
if __name__ == '__main__':
dest = 'hello'
video_path = r'H:\cn\1.1.mp4'
video_language = r'zh-CN'
# 获取视频文件的文件名
file_name = get_file_name(video_path)
audio_file = file_name + '.wav'
# 加载视频
video = VideoFileClip(video_path)
# 将视频转化为音频
video.audio.write_audiofile(audio_file, ffmpeg_params=['-ar', '16000', '-ac', '1'])
# 对语音分片实现语音识别,得到文字信息
# 打开音频wav文件
sound = AudioSegment.from_file(audio_file)
# 返回分割好的声音片段
timestamp_list = detect_nonsilent(sound, 500, sound.dBFS * 1.3, 1)
# 调用识别器
r = sr.Recognizer()
idx = 0
srt_text = ''
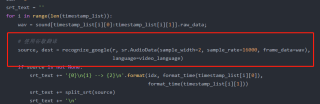
for i in range(len(timestamp_list)):
wav = sound[timestamp_list[i][0]:timestamp_list[i][1]].raw_data;
# 使用谷歌翻译
source, dest = recognize_google(r, sr.AudioData(sample_width=2, sample_rate=16000, frame_data=wav),
language=video_language)
if source is not None:
srt_text += '{0}\n{1} --> {2}\n'.format(idx, format_time(timestamp_list[i][0]),
format_time(timestamp_list[i][1]))
srt_text += split_srt(source)
srt_text += '\n'
srt_text += split_srt(dest)
srt_text += '\n'
idx = idx + 1
print(str(i) + ":" + source + '->' + dest);
d = timestamp_list[i][1] - timestamp_list[i][0]
print("Section is :", timestamp_list[i], "duration is:", d)
generate_srt(file_name, srt_text)