import re
import requests
from fake_useragent import UserAgent
headers = {"User-Agent" : UserAgent().random}
PaperUrl = 'https://www.sciencedirect.com/search/api?
param = {'qs': 'car tourism',
'pub': 'Tourism Management',
'cid': 271716,
't': 'ZNS1ixW4GGlMjTKbRHccgTrm%2F%2BWBqyPRxQfBpALgy5yV6QyxSK1wRiqbcvDgEHZYlsq2d8X3OTZN7UG%2FlCjz%2Bm6L4PUF0k6HOGFg%2Fg7RmusmZ0Q28STvJ9SQp7Q5GFRFvKdDbfVcomCzYflUlyb3MA%3D%3D',
'hostname': 'www.sciencedirect.com'}
page_text = requests.get(PaperUrl, params = param, headers = headers).text
print(page_text)
有人知道如何能爬到吗
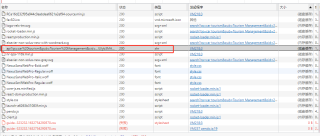
要爬的网址页面:https://www.sciencedirect.com/search?qs=car%20tourism&pub=Tourism%20Management&cid=271716
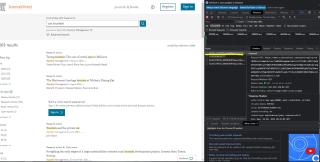
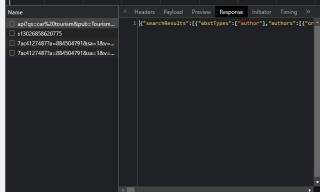
是正常响应的
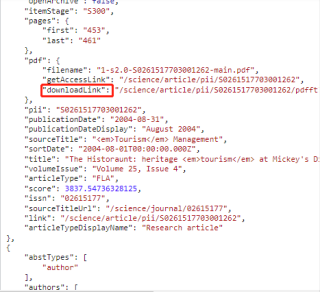
F12开发工具中找到的api接口(其中里面有文章名称、作者名、发表日期等):https://www.sciencedirect.com/search/api?qs=car%20tourism&pub=Tourism%20Management&cid=271716&t=ZNS1ixW4GGlMjTKbRHccgTrm%252F%252BWBqyPRxQfBpALgy5yV6QyxSK1wRiqbcvDgEHZYlsq2d8X3OTZN7UG%252FlCjz%252Bm6L4PUF0k6HOGFg%252Fg7RmusmZ0Q28STvJ9SQp7Q5GFRFvKdDbfVcomCzYflUlyb3MA%253D%253D&hostname=www.sciencedirect.com
但是返回的结果是空的,状态代码401.请问怎么办啊