# -*- codeing = utf-8 -*-
#豆瓣电影前250信息,写入csv/txt文件
import requests, csv, re
from lxml import etree
from bs4 import BeautifulSoup as bs
import urllib
from urllib import request
k = 0
n = 1
movieData250 = []
#读取每一个网页25个电影信息
def info25():
movieData = []
for i in range(0,25):
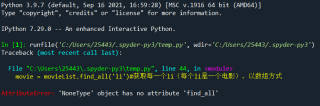
name = movie[i].find('span',class_="title").string#获得影片名称
score = movie[i].find('span',class_="rating_num").string#获得影片评分
num = movie[i].find('div',class_="star").find_all('span')[-1].string.strip('人评价')#获得影片评价人数
quote = movie[i].find('span',class_="inq")#获得影片短评
if quote is None:
quote = "暂无"
else:
quote = quote.string
#movieData[i] = [i+1,name,score,num,quote]
movieData.append([i+1+k,name,score,num,quote])
#print(movieData)
return movieData
#movieData250 = movieData250 + movieData
while(k == 0):
h="https://movie.douban.com/top250"
#设置浏览器代理,它是一个字典
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
request = urllib.request.Request(h, headers=headers)
resp = urllib.request.urlopen(request)
html_data = resp.read().decode('utf-8')
soup = bs(html_data,'lxml')
#print(soup.prettify())
#movieList=soup.find('ol')#寻找第一个ol标签,得到所有电影
#movieList=soup.find('ol',class_="grid_view")#以下两种方法均可
movieList = soup.find('ol',attrs={'class':"grid_view"})
movie = movieList.find_all('li')#获取每一个li(每个li是一个电影),以数组方式
movieData250 +=info25()
k += 25
while(k<250):
h = "https://movie.douban.com/top250?start=" + str(k) + "&filter="
#设置浏览器代理,它是一个字典
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
request = urllib.request.Request(h, headers=headers)
resp = urllib.request.urlopen(request)
html_data=resp.read().decode('utf-8')
soup=bs(html_data,'lxml')
#print(soup.prettify())
#movieList=soup.find('ol')#寻找第一个ol标签,得到所有电影
#movieList=soup.find('ol',class_="grid_view")#以下两种方法均可
movieList=soup.find('ol',attrs={'class':"grid_view"})
movie=movieList.find_all('li')#获取每一个li(每个li是一个电影),以数组方式
movieData250 += info25()
k+=25
#print(movieData250)
#将数组movieData250写入文件txt
import codecs
s ="—————————豆瓣电影top250——————————\r\n"
f = codecs.open("豆瓣电影top250.txt",'w','utf-8')
f.write(s)
for i in movieData250:
f.write(str(i)+'\r\n') #\r\n为换行符
f.close()










